Ollama : L'IA Générative en Local pour Tous
Depuis novembre 2022, l'IA générative connaît un essor fulgurant, capable de créer du texte, des images, de la musique et du code. Pour profiter pleinement de cette révolution, Ollama fait son apparition, offrant la possibilité de faire tourner des modèles d'intelligence artificielle directement sur votre machine. Cet article vous guidera à travers l'installation et l'utilisation d'Ollama, rendant l'IA générative accessible sans nécessiter de compétences de data scientist, mais plutôt un PC performant avec une carte graphique, l'outil Docker et une bonne dose de curiosité.
Pourquoi Ollama est une Révolution
L'intelligence artificielle, bien que puissante, est également énergivore en termes de matériel et de données. Ollama vient changer la donne en permettant l'exécution locale des modèles, ce qui présente plusieurs avantages majeurs :
Réduction de la Consommation Énergétique
L'exécution locale des modèles évite le recours massif aux datacenters, qui sont de grands consommateurs d'énergie. Une requête sur ChatGPT, par exemple, consomme dix fois plus d'électricité qu'une recherche sur Google, selon l'Agence Internationale de l'Énergie. Le bilan carbone d'une requête dépend fortement du mix énergétique du datacenter. Alors que les États-Unis concentrent une part importante des centres de données mondiaux avec un mix énergétique encore carboné, leur hébergement en France pourrait réduire l'empreinte carbone jusqu'à dix fois grâce à une énergie plus décarbonée.
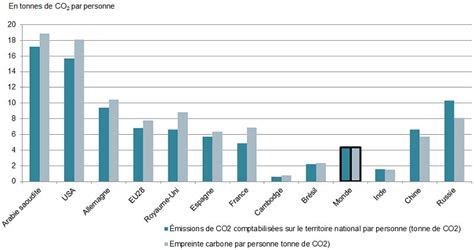
Optimisation des Ressources Matérielles
Ollama fonctionne sur des machines locales et s'adapte aux capacités disponibles. Cette approche favorise le Green IT en permettant d'utiliser le matériel existant sans nécessiter de remplacements fréquents.
Contrôle et Personnalisation des Modèles
Avec Ollama, les utilisateurs ont la liberté de choisir des modèles spécifiquement optimisés pour leurs besoins, évitant ainsi l'utilisation de modèles surdimensionnés et énergivores. Une fois connecté à Open WebUI, Ollama propose une interface conviviale similaire à ChatGPT.
Prérequis Techniques pour Ollama
Il est important de noter que les Grands Modèles de Langage (LLM) nécessitent un GPU (carte graphique) plutôt qu'un CPU. Leur architecture est optimisée pour le calcul parallèle, ce qui est essentiel pour le traitement efficace de ces modèles.
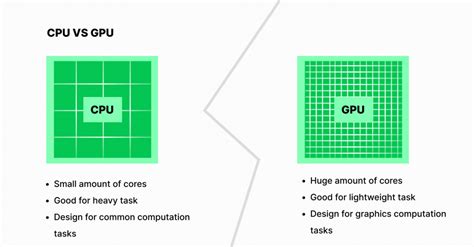
Installation et Utilisation d'Ollama
Une fois Ollama et son interface WebUI installés, vous accédez à une bibliothèque riche de plus de 150 modèles disponibles. L'interface permet de sélectionner les modèles par usage : embedding (RAG), vision (analyse d'images), tools (code, etc.).
La Bibliothèque de Modèles
Chaque modèle téléchargeable pèse au minimum 4,7 Go, ce qui peut prendre quelques minutes. Parmi les modèles disponibles, le BGE-M3 offre une grande flexibilité pour la récupération d'informations (RAG) grâce à ses capacités de recherche dense, multi-vecteurs et sparse.
Il est possible de télécharger les modèles directement depuis l'interface WebUI. La patience est de mise lors du téléchargement.
WebUI : L'Interface Intuitive
WebUI est une interface web, similaire à celle de ChatGPT, qui facilite l'interaction avec les modèles d'IA téléchargés via Ollama. Elle est conçue pour être intuitive et accessible, offrant une expérience fluide aux débutants comme aux utilisateurs avancés. L'interface permet de choisir différents modèles d'IA en fonction de la tâche à accomplir.
Spécialisation des Modèles avec OpenWebUI
Le site OpenWebUI propose des exemples de spécialisation des modèles Ollama, visant à faciliter leur utilisation avancée pour des cas concrets plébiscités par la communauté. Pour ajouter un modèle à votre interface locale OpenWebUI, il suffit de le rechercher sur le site, de cliquer sur "Get", puis sur "Import to WebUI". Le nouveau modèle apparaît alors dans votre interface locale et est prêt à être utilisé.
Par exemple, il est possible d'engager une conversation avec un modèle qui pourrait fournir des explications sur des phénomènes comme la couleur du ciel ou le coucher du soleil.
Exemple d'interaction : Pourquoi le ciel est bleu ?
Une question classique ! La couleur du ciel est due à l'interaction des atomes d'azote (N2) et de dioxygène (O2) dans l'atmosphère terrestre avec la lumière solaire. Lorsque les rayons solaires pénètrent dans l'atmosphère, ils sont composés de toutes les couleurs du spectre visible. Les molécules d'azote et de dioxygène absorbent les rayons rouges et oranges. Les rayons bleus, ayant une longueur d'onde plus courte, sont réfléchis par ces molécules et atteignent nos yeux.
Exemple d'interaction : Pourquoi le ciel devient-il rouge au coucher du soleil ?
La couleur rouge au coucher du soleil est due à une combinaison de phénomènes :
- La lumière solaire parcourt une plus grande distance dans l'atmosphère, favorisant la dispersion des rayons courts (bleus et verts) et laissant passer les rayons longs (rouges, oranges et jaunes).
- Les molécules d'ozone (O3) dans l'atmosphère absorbent les rayons bleus et verts, laissant les couleurs rouges et jaunes dominer.
- Le Soleil lui-même change de couleur à mesure qu'il descend sur l'horizon, émettant une lumière de plus haute fréquence (bleue et verte).
Capacités d'Analyse Visuelle avec LLaVA
Le modèle LLaVA sur Ollama offre des capacités avancées d'analyse visuelle. Il peut identifier les éléments dans une image, comprendre le contexte et les relations entre eux. La requête de base pour analyser une image nécessite que l'attribut `images` corresponde à la conversion de l'image au format "base 64".
Par exemple, une photographie professionnelle d'un espace de travail moderne, décoré avec des meubles contemporains et des plantes, peut être analysée. Le modèle peut décrire la présence de bancs, d'une cheminée, d'un revêtement mural décoratif et d'un sol en matériau dur. Il peut également identifier des éléments spécifiques comme une représentation artistique d'une canette de Pepsi ou la présence d'un chien et d'un chat blancs sur une surface douce, en décrivant leurs caractéristiques (couleur des yeux, colliers).

API Ollama pour les Développeurs
Ollama met à disposition des API puissantes pour simplifier l'intégration et l'interaction des développeurs avec les modèles d'IA.
- Completion : Génère des complétions de texte à partir d'un modèle local en utilisant l'endpoint `/generate` (pour la génération de texte en un seul tour).
- Chat : Génère des complétions de texte à partir d'un modèle local en utilisant l'endpoint `/chat` (pour les conversations multi-tours).
Génération d'Images avec Stable Diffusion XL sur Raspberry Pi
Il est également possible de générer des images de manière locale, même sur des appareils moins puissants comme le Raspberry Pi, grâce à des projets innovants.
OnnxStream : L'Optimisation pour les Petits Appareils
OnnxStream est un projet open-source créé par Vito Plantamura, initialement conçu pour faire tourner Stable Diffusion 1.5 sur un Raspberry Pi Zero 2. Il a depuis été étendu pour supporter Stable Diffusion XL 1.0 et Stable Diffusion XL Turbo 1.0. Ce projet minimise la consommation mémoire, même si cela peut augmenter la latence d'inférence.
Configuration Technique
Pour utiliser OnnxStream, vous aurez besoin :
- D'un Raspberry Pi 5 (ou un modèle antérieur, bien que plus lent).
- D'une carte SD d'au moins 16 Go avec une distribution Linux installée (les poids du modèle SDXL Turbo pèsent environ 8 Go).
- D'une connexion internet.
Installation et Configuration d'OnnxStream
- Construction de XNNPack : Installez XNNPack, une bibliothèque de Google fournissant des opérateurs d'inférence de réseaux neuronaux très efficaces. Il est recommandé d'utiliser la version vérifiée par le créateur d'OnnxStream pour éviter les problèmes de compatibilité.
- Construction d'OnnxStream : Compilez le projet OnnxStream. Assurez-vous de spécifier le répertoire où XNNPack a été cloné.
- Téléchargement des Poids du Modèle : Téléchargez les poids du modèle SDXL Turbo. Ce processus peut être long en raison de la taille des fichiers. Vous pouvez également télécharger les poids pour Stable Diffusion 1.5 et Stable Diffusion XL 1.0 Base depuis le dépôt GitHub d'OnnxStream. Assurez-vous d'avoir suffisamment d'espace sur votre carte SD.
Génération d'Images avec SDXL Turbo
Pour générer des images, vous pouvez utiliser la commande suivante dans le terminal :
./sd --turbo --models-path /home/admin/stable-diffusion-xl-turbo-1.0-onnxstream --prompt "An astronaut riding a horse on Mars" --steps 1 --output astronaut.png
Vous pouvez remplacer le prompt par votre propre description. Le paramètre `--steps 1` est utilisé car SDXL Turbo ne nécessite que peu d'étapes pour générer une image de qualité. D'autres arguments comme `--neg-prompt` (pour les modèles autres que SDXL Turbo), `--steps` pour le nombre d'étapes, et `--seed` pour la graine aléatoire sont également disponibles.
Sur un Raspberry Pi 5, chaque étape de diffusion prend environ 1 minute, et le temps total de génération d'une image, incluant le pré-traitement et le décodage, est d'environ 3 minutes.

Cas d'Usage et Perspectives
La génération d'images en quelques minutes ouvre de nombreuses possibilités. Un cas d'usage évident est un cadre photo numérique qui génère une nouvelle image toutes les quelques minutes. Un projet existant utilise OnnxStream sur un Raspberry Pi Zero 2 W pour générer des images pour des articles de presse et les afficher sur un écran e-ink.
Il est également possible d'avoir votre propre générateur d'images localisé, capable de produire des images de qualité sans monopoliser des ressources informatiques majeures sur votre réseau. Cela permet de s'affranchir des modèles en ligne pour un usage personnel.

L'essor des IA Locales et les Avancées Techniques
L'activité des développeurs en IA sur PC est en pleine expansion, stimulée par la qualité croissante des petits modèles de langage (SLM) et des modèles de diffusion tels que FLUX.2, GPT-OSS-20B et Nemotron 3 Nano. Parallèlement, les frameworks d'IA pour PC, y compris ComfyUI, llama.cpp, Ollama et Unsloth, gagnent rapidement en popularité, doublant leur utilisation au cours de la dernière année.
Optimisations pour les GPU NVIDIA
ComfyUI a optimisé ses performances sur les GPU NVIDIA grâce à PyTorch-CUDA et a introduit le support des formats NVFP4 et FP8. Ces formats quantifiés permettent des économies de mémoire de 60% et 40% respectivement, tout en accélérant les performances. Des techniques comme le RMS & RoPE Fusion permettent de fusionner des opérateurs gourmands en bande passante mémoire dans les transformeurs de diffusion pour réduire l'usage mémoire et la latence.
Le support de l'exécution concurrente des flux CUDA accélère l'inférence des modèles, et l'utilisation de Flash Attention est désormais standard sur de nombreux modèles.
Modèles Audio-Vidéo et IA Générative
NVIDIA et Lightricks collaborent pour publier les poids du modèle LTX-2, un modèle audio-vidéo avancé capable de concurrencer les modèles cloud. Ce modèle open-source et prêt pour la production peut générer jusqu'à 20 secondes de contenu AV synchronisé en résolution 4K. Les poids du modèle sont disponibles en BF16 et NVFP8.

Défis et Solutions pour les Agents Locaux
Les cas d'usage des agents privés et locaux sont illimités, mais construire des agents fiables, reproductibles et de haute qualité reste un défi. La qualité des LLM peut se dégrader lors de la distillation et de la quantification pour s'adapter à une VRAM limitée sur PC. Pour pallier cela, les développeurs utilisent le fine-tuning et la génération augmentée par récupération (RAG).
Le modèle Nemotron 3 Nano, un modèle MoE de 32 milliards de paramètres optimisé pour l'IA agentique et le fine-tuning, se distingue par ses performances sur des tâches variées comme le codage, le suivi d'instructions, et le raisonnement contextuel. Sa nature open-source, avec des poids, recettes et jeux de données largement disponibles, facilite la personnalisation par les développeurs.
Pour la RAG, NVIDIA s'est associé à Docling, un package développé chez IBM et contribué à la Linux Foundation, pour ingérer, analyser et traiter des documents en langage compréhensible pour les pipelines RAG.
Génération d'Images Locale : Fooocus et AUTOMATIC1111
La question de savoir comment générer des images sur son propre ordinateur est de plus en plus pertinente. Fooocus est un environnement gratuit, open-source et entièrement local (sans connexion internet) pour créer des images à l'aide de modèles basés sur Stable Diffusion.
Fooocus offre des fonctionnalités telles que :
- Mise à l'échelle d'images (upscaling)
- Extension d'images (outpainting)
- Remplissage d'images (inpainting)
- Génération de variations
- Description d'images
- Utilisation de prompts négatifs
Il est important de noter que la génération d'images peut prendre un temps considérable. Les mots-clés utilisés influencent le style de l'image, rendant parfois difficile la création d'une série cohérente.

L'inpainting permet de modifier ou de changer complètement une partie du contenu d'une image. Par exemple, il est possible d'ajouter un personnage à une image existante en activant l'option "input image" et en téléchargeant l'image à modifier.
Ces générateurs peuvent également être utilisés pour créer des ébauches et des propositions pour divers appareils domotiques, tels que des contrôleurs de chauffage, des stations météorologiques ou des panneaux tactiles.
Fooocus et AUTOMATIC1111 sont les deux interfaces open-source les plus utilisées. Il est à noter que les œuvres générées par IA n'ont pas de droit d'auteur, l'auteur du prompt étant considéré comme le propriétaire de l'œuvre.
Pour optimiser la génération, il est conseillé d'utiliser un faible nombre d'étapes d'échantillonnage (Sampling Steps, par exemple 10) et un petit nombre de lots (Batch Count) pour un aperçu, puis de relancer la génération avec une graine (Seed) choisie à des étapes plus élevées ou avec l'option "High-Res fix".
Les modèles de type checkpoints (.safetensors ou .ckpt) pèsent généralement entre 4 et 9 Go chacun.
L'accélération matérielle est prise en compte sur Mac, tandis que sur Windows ou GNU/Linux, il peut être nécessaire de renseigner l'identifiant matériel de votre carte graphique Nvidia RTX ou AMD pour activer cette option.
INSTALLER en local Fooocus 🔥 Le Meilleur GÉNÉRATEUR d'IMAGES IA GRATUIT
tags: #llama #stable #diffusion #xl #nvidia #ieeespectrum