Stable Diffusion : Comprendre et Gérer les Concepts NSFW
Stable Diffusion est un modèle d'apprentissage profond de type texte-à-image, publié en 2022 et basé sur des techniques de diffusion. Il s'agit d'un modèle de diffusion latente, une sorte de réseau neuronal artificiel génératif profond.
Origines et Architecture
Stable Diffusion trouve son origine dans un projet nommé Latent Diffusion, développé en Allemagne par des chercheurs de l'Université Louis-et-Maximilien de Munich et de l'Université de Heidelberg. Les modèles de diffusion, introduits en 2015, sont entraînés dans le but d'éliminer des applications successives de bruit gaussien sur des images d'entraînement, ce qui peut être considéré comme une séquence de auto-encodeurs débruiteurs.
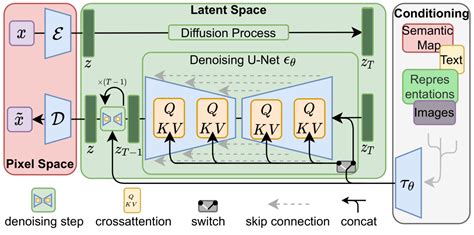
Stable Diffusion se compose de trois parties principales :
- Le Variational Autoencoder (VAE) : Ce composant compresse l'image de l'espace pixel vers un espace latent de dimension réduite, capturant ainsi une signification sémantique plus fondamentale de l'image. Pendant la diffusion avant, du bruit gaussien est itérativement appliqué à la représentation latente compressée.
- Le bloc U-Net : Composé d'un backbone ResNet, ce bloc débruite la sortie de la diffusion avant en sens inverse pour obtenir une représentation latente. L'étape de débruitage peut être conditionnée de manière flexible par une chaîne de texte, une image ou une autre modalité.
- Un encodeur de texte optionnel.
La version 3.0 a complètement modifié le backbone, introduisant l'architecture Transformer. Cette architecture, nommée "multimodal diffusion transformer (MMDiT)", possède trois "pistes" : une pour l'encodage de texte original, une pour l'encodage de texte transformé, et une pour l'encodage d'image (dans l'espace latent). Le terme "multimodal" indique qu'elle mélange les encodages de texte et d'image au sein de ses opérations.
Entraînement et Jeu de Données
Stable Diffusion a été entraîné sur des paires d'images et de légendes provenant de LAION-5B. Il s'agit d'un jeu de données publiquement disponible, dérivé des données de Common Crawl collectées sur le web. Ce jeu de données contient 5 milliards de paires image-texte, classifiées par langue et filtrées en ensembles de données distincts selon la résolution, la probabilité prédite de contenir un filigrane et un score esthétique prédit.
Limitations et Défis
Dégradation de la Qualité et Inexactitudes
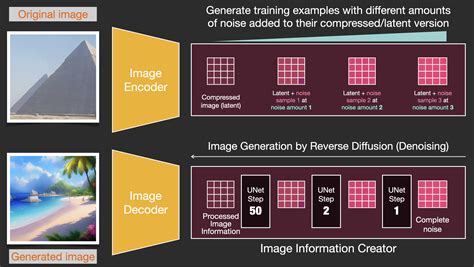
Stable Diffusion rencontre des problèmes de dégradation et d'inexactitudes dans certains scénarios. Les premières versions du modèle étaient entraînées sur un jeu de données composé d'images de résolution 512x512. Par conséquent, la qualité des images générées se dégrade notablement lorsque les spécifications de l'utilisateur s'écartent de cette résolution "attendue". La version 2.0 de Stable Diffusion a introduit la capacité de générer nativement des images en résolution 768x768.
Génération d'Éléments Humains et de Texte
Un autre défi réside dans la génération des membres humains, due à la mauvaise qualité des données des membres dans la base de données LAION. Le modèle est insuffisamment entraîné pour reproduire les membres et les visages humains en raison du manque de caractéristiques représentatives dans la base de données. La sollicitation du modèle pour générer de telles images peut le confondre. De plus, Stable Diffusion est incapable de générer des ambigrammes lisibles et certaines autres formes de texte et de typographie.
Accessibilité et Personnalisation
L'accessibilité pour les développeurs individuels peut également être un problème. Pour personnaliser le modèle pour de nouveaux cas d'utilisation non inclus dans le jeu de données, comme la génération de personnages d'anime ("waifu diffusion"), de nouvelles données et un entraînement supplémentaire sont nécessaires. Des adaptations affinées de Stable Diffusion, créées par un réentraînement additionnel, ont été utilisées pour une variété de cas d'utilisation, de l'imagerie médicale à la musique générée algorithmiquement.
Cependant, ce processus de fine-tuning est sensible à la qualité des nouvelles données. Des images de faible résolution ou des résolutions différentes de celles des données originales peuvent non seulement échouer à apprendre la nouvelle tâche, mais aussi dégrader la performance globale du modèle. Même lorsque le modèle est entraîné sur des images de haute qualité, il est difficile pour les individus d'exécuter les modèles sur des appareils électroniques grand public.
Biais Algorithmique et Solutions
Biais Liés aux Données d'Entraînement
Les créateurs de Stable Diffusion reconnaissent le potentiel de biais algorithmique, le modèle ayant été principalement entraîné sur des images avec des descriptions en anglais. En conséquence, les images générées renforcent les biais sociaux et sont issues d'une perspective occidentale, car les créateurs notent que le modèle manque de données provenant d'autres communautés et cultures.
Personnalisation et Techniques d'Adaptation
Pour remédier aux limitations de l'entraînement initial du modèle, les utilisateurs finaux peuvent choisir de mettre en œuvre un entraînement supplémentaire pour affiner les sorties de génération afin de correspondre à des cas d'utilisation plus spécifiques, un processus également appelé personnalisation.
- Embeddings (Plongements) : Un "embedding" peut être entraîné à partir d'une collection d'images fournies par l'utilisateur, permettant au modèle de générer des images visuellement similaires chaque fois que le nom de l'embedding est utilisé dans une invite de génération. Les embeddings sont basés sur le concept de "textual inversion", développé par des chercheurs de l'Université de Tel Aviv en 2022 avec le soutien de Nvidia. Dans ce concept, les représentations vectorielles de jetons spécifiques utilisés par l'encodeur de texte du modèle sont liées à de nouveaux pseudo-mots.
- Hypernetworks : Un hypernetwork est un petit réseau neuronal pré-entraîné appliqué à différents points d'un réseau neuronal plus grand. Il fait référence à la technique créée par le développeur de NovelAI, Kurumuz, en 2021, initialement destinée aux modèles transformer de génération de texte.
Fonctionnalités de Génération et Contrôle
Génération Texte-à-Image (txt2img)
Le script d'échantillonnage texte-à-image de Stable Diffusion, connu sous le nom de "txt2img", consomme une invite textuelle ainsi que divers paramètres optionnels couvrant les types d'échantillonnage, les dimensions de l'image de sortie et les valeurs de graine (seed). Chaque génération txt2img impliquera une valeur de graine spécifique qui affecte l'image de sortie.
Des fonctionnalités txt2img supplémentaires sont fournies par des implémentations front-end de Stable Diffusion, qui permettent aux utilisateurs de modifier le poids accordé à des parties spécifiques de l'invite textuelle. Les marqueurs d'emphase permettent aux utilisateurs d'ajouter ou de réduire l'emphase sur des mots-clés en les plaçant entre crochets.
Prompts Négatifs
Une méthode alternative pour ajuster le poids des parties de l'invite sont les "prompts négatifs". Les prompts négatifs sont une fonctionnalité incluse dans certaines implémentations front-end, y compris le service cloud DreamStudio de Stability AI. Ils permettent à l'utilisateur de spécifier des invites que le modèle doit éviter lors de la génération d'images.
Génération Image-à-Image (img2img)
Stable Diffusion inclut également un autre script d'échantillonnage, "img2img". Ce script consomme une invite textuelle, le chemin d'accès à une image existante et une valeur de force (strength) comprise entre 0.0 et 1.0. Le script produit une nouvelle image basée sur l'image d'origine, qui présente également des éléments fournis dans l'invite textuelle. La valeur de force indique la quantité de bruit ajoutée à l'image de sortie.
Il existe différentes méthodes pour effectuer img2img. La capacité d'img2img à ajouter du bruit à l'image d'origine le rend potentiellement utile pour l'anonymisation de données et l'augmentation de données, où les caractéristiques visuelles des données d'image sont modifiées et anonymisées. Le même processus peut également être utile pour la mise à l'échelle d'images (upscaling), où la résolution d'une image est augmentée, avec potentiellement plus de détails ajoutés à l'image. De plus, Stable Diffusion a été expérimenté comme outil de compression d'images.
Contrôle et Personnalisation Avancés
ControlNet
ControlNet est une architecture de réseau neuronal conçue pour contrôler les modèles de diffusion en incorporant des conditions supplémentaires. Il duplique les poids des blocs du réseau neuronal en une copie "verrouillée" et une copie "entraînable". La copie "entraînable" apprend la condition souhaitée, tandis que la copie "verrouillée" préserve le modèle original. Cette approche garantit que l'entraînement avec de petits ensembles de données d'images appariées ne compromet pas l'intégrité des modèles de diffusion prêts à la production.
Le "zero convolution" est une convolution 1x1 avec des poids et des biais initialisés à zéro. Avant l'entraînement, toutes les zero convolutions produisent une sortie nulle, empêchant toute distorsion causée par ControlNet. Aucune couche n'est entraînée à partir de zéro ; le processus reste du fine-tuning, préservant le modèle original.
ControlNet est couramment utilisé pour modifier la génération d'une image en se basant sur une image d'entrée qui mappe les propriétés souhaitées dans l'image finale. Les types courants d'images de mappage incluent une carte de profondeur, des contours ou une ou plusieurs poses squelettiques.
Gestion des Concepts NSFW et Sécurité
Les modèles texte-à-image, tels que Stable Diffusion, peuvent involontairement apprendre des concepts inappropriés à partir de vastes données d'entraînement non filtrées, ce qui entraîne divers risques éthiques et commerciaux. Spécifiquement, les images générées par le modèle peuvent présenter du contenu Not Safe For Work (NSFW) et des violations de droits d'auteur de style. Les invites qui conduisent à ces problèmes ne contiennent souvent pas de mots explicites inappropriés ; elles contiennent plutôt des termes obscurs et associatifs, appelés invites implicitement dangereuses.
Approches pour l'Effacement des Concepts
Des recherches se concentrent sur trois approches principales pour atténuer ce problème :
- Nettoyage des Données (Data Cleansing) : Filtrer les images dangereuses des ensembles de données d'entraînement avant l'entraînement du modèle. Par exemple, Stable Diffusion 2.0 utilise cette stratégie pour réduire l'exposition au contenu dangereux.
- Fine-tuning de Sécurité (Safety Fine-Tuning) : Ajuster les modèles pré-entraînés pour supprimer les réponses dangereuses. Les techniques incluent l'ablation de concepts et les algorithmes basés sur DPO.
- Filtrage et Correction en Phase de Génération : Bloquer les invites dangereuses lors de l'inférence à l'aide de classificateurs NSFW (par exemple, Stable Diffusion et Midjourney) ou guider dynamiquement les sorties via des méthodes comme SLD et ESD-u, qui modifient la prédiction de bruit pendant l'entraînement ou l'inférence.
PromptSan : Une Méthode de Désinfection des Invites
Pour relever ces défis, des méthodes comme PromptSan ont été proposées. PromptSan vise à "désinfecter" les invites potentiellement dangereuses sans modifier l'architecture du modèle ni dégrader la capacité de génération.
- PromptSan-Modify : Cette variante opère pendant la phase d'inférence. Elle identifie et remplace itérativement les jetons dangereux dans les invites d'entrée à l'aide de classificateurs NSFW textuels, les déplaçant vers une zone sûre du classificateur.
- PromptSan-Suffix : Cette variante s'entraîne pendant la phase d'entraînement en optimisant une séquence de jetons suffixe qui neutralise l'intention dangereuse tout en passant les vérifications des classificateurs NSFW textuels et d'image.
Ces méthodes permettent une intervention légère sur les invites d'entrée pour purifier activement les sémantiques dangereuses. Elles visent à garantir que les images générées soient sûres tout en préservant la qualité et la préservation des concepts sûrs.
Aspects Légaux et Licences
Contrairement à des modèles comme DALL-E, Stable Diffusion rend son code source disponible, ainsi que le modèle (poids pré-entraînés). Avant Stable Diffusion 3, il appliquait la licence Creative ML OpenRAIL-M, une forme de Responsible AI License (RAIL). Cette licence interdit certains cas d'utilisation, notamment le crime, la diffamation, le harcèlement, le "doxing", l'exploitation de mineurs, la fourniture de conseils médicaux, la création automatique d'obligations légales, la production de preuves légales, et la discrimination ou le préjudice à des individus ou des groupes basés sur le comportement social ou les caractéristiques personnelles.
Affaire Getty Images contre Stability AI
En janvier 2023, Getty Images a intenté une action en justice contre Stability AI devant la Haute Cour d'Angleterre, alléguant une violation importante de ses droits de propriété intellectuelle. Getty Images a affirmé que l'entraînement et le développement de Stable Diffusion impliquaient l'utilisation non autorisée de ses images, téléchargées sur des serveurs et des ordinateurs potentiellement situés au Royaume-Uni. Stability AI a demandé un jugement sommaire inversé et/ou le rejet de deux chefs d'accusation : celui de l'entraînement et du développement, et celui de la contrefaçon secondaire de droits d'auteur. La Haute Cour a cependant refusé de rejeter ces chefs d'accusation, leur permettant de suivre leur cours jusqu'au procès.
À qui appartiennent les droits d’auteur d’une œuvre créée par l’intelligence artificielle ?
tags: #stable #diffusion #nsfw #concepts