Installation et Utilisation de Stable Diffusion XL sous Linux
L'intelligence artificielle continue de progresser à pas de géant, et la génération d'images par IA est un domaine particulièrement fascinant. Bien que de nombreux outils en ligne existent, ils présentent souvent des limitations pour les utilisateurs gratuits : accès restreint aux modèles, génération d'images lente, personnalisation limitée et dépendance vis-à-vis de la plateforme. Pour surmonter ces contraintes, il est possible de déployer ces modèles localement sur votre propre machine.
Ce tutoriel se concentre sur l'installation et l'utilisation de Stable Diffusion WebUI, une interface graphique conviviale développée par Automatic1111, spécifiquement pour les systèmes d'exploitation Linux (Ubuntu/Debian). L'objectif est de vous permettre de générer des images avec l'IA directement sur votre ordinateur, offrant ainsi plus de contrôle et de confidentialité.
Prérequis pour l'installation sous Linux
Avant de commencer l'installation de Stable Diffusion WebUI, assurez-vous que votre système Linux dispose des éléments nécessaires. La procédure est conçue pour être aussi simple que possible, et le gestionnaire de paquets apt vous indiquera si certains composants sont déjà installés.
Installation des dépendances
La première étape consiste à installer toutes les dépendances requises pour le bon fonctionnement de Stable Diffusion WebUI sur votre distribution Linux. Le système se chargera de télécharger et d'installer les paquets nécessaires. Si un paquet est déjà présent, le gestionnaire de paquets passera simplement au suivant.
Il est également crucial de s'assurer que vous disposez des pilotes les plus récents, en particulier si vous utilisez une carte graphique Nvidia.
Installation de Python 3
Si Python 3 n'est pas déjà installé sur votre système, vous devrez l'installer. Python est un langage de programmation essentiel pour de nombreux outils d'IA.
Installation de Stable Diffusion WebUI
Une fois les dépendances satisfaites, vous pouvez procéder au téléchargement et à l'installation de Stable Diffusion WebUI. Cet outil servira d'interface pour interagir avec les modèles de génération d'images.
Téléchargement du dépôt
Vous pouvez télécharger le dépôt de stable-diffusion-webui en utilisant Git. Assurez-vous de vous trouver dans le répertoire où vous souhaitez installer l'outil (par exemple, /home/AI).
Exécutez la commande suivante pour cloner le dépôt :
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Si vous avez déjà une version d'Automatic1111 installée, vous pouvez simplement mettre à jour votre instance existante en exécutant le fichier webui-user.bat (ou webui.sh sous Linux) avec la commande git pull ajoutée. Cela permet à votre ligne de commande de vérifier le dépôt A1111 en ligne et de mettre à jour votre instance.
Configuration et Premiers Pas avec Stable Diffusion
Après le téléchargement, le programme se chargera de récupérer le modèle par défaut, Stable Diffusion 1.5. Vous êtes alors presque prêt à commencer à générer des images en local.
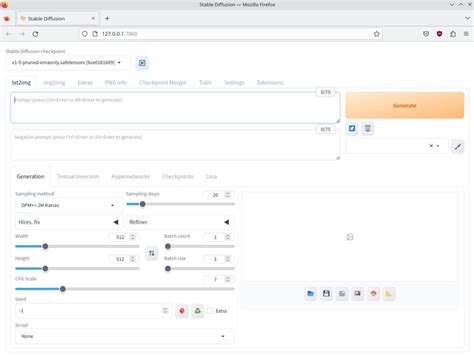
Lancement de l'interface WebUI
Pour lancer l'interface, exécutez le script approprié : webui.sh sous Linux.
Pour les utilisateurs disposant de cartes graphiques avec 8 Go ou 10 Go de VRAM, il est recommandé d'utiliser le fichier batch webui-user.bat avec des arguments supplémentaires tels que --xformers --no-half-vae. Ces options optimisent l'utilisation de la mémoire et réduisent les erreurs de type "CUDA out of memory".
Si vous utilisez torch >= 2.0, vous pouvez améliorer la vitesse d'inférence de 20 à 30 % en utilisant torch.compile.
Utilisation de l'interface
Une fois l'interface lancée, vous remarquerez une section en haut à gauche où vous pouvez sélectionner le modèle de base à utiliser. Pour Stable Diffusion XL, assurez-vous de sélectionner le modèle XL.
Pour une génération d'images optimale avec Stable Diffusion XL, il est recommandé d'utiliser des résolutions comprises entre 768x768 et 1024x1024 pixels. Des résolutions plus élevées produiront des images plus nettes mais nécessiteront plus de temps de génération.
Vous pouvez également ajuster le nombre d'étapes d'échantillonnage (sampling steps) et la méthode d'échantillonnage (sampling method), qui influencent significativement le résultat final. Généralement, 20 à 60 étapes sont considérées comme de bonnes valeurs, et le sampler "DPM++ SDE Karras" donne d'excellents résultats. Une valeur plus basse peut conduire à des résultats plus créatifs et moins littéraux.
Génération d'images avec Stable Diffusion XL
Une fois que vous avez configuré vos paramètres, vous pouvez entrer votre prompt (description textuelle de l'image souhaitée) et éventuellement un Negative prompt (ce que vous ne voulez pas voir dans l'image). Cliquez ensuite sur "Generate". En quelques secondes, votre image devrait être produite, le temps de génération dépendant de la puissance de votre GPU.
Personnalisation des dimensions
Pour les meilleurs résultats, il est conseillé d'utiliser une résolution de 1024x1024px. Cependant, si vous souhaitez générer des images plus hautes ou plus larges, l'objectif est que la somme des dimensions soit d'environ 2048px.
Utilisation du modèle Refiner
Si vous avez installé le modèle refiner, vous pouvez envoyer votre image générée à la section img2img. Là, vous pouvez passer au modèle refiner pour appliquer des modifications et des ajustements à l'image originale.
Stable Diffusion VS Comfy (SDXL Base & Refiner) ستيبل ديفيوجن ريفاينر
Modèles Alternatifs et Optimisations
Stable Diffusion XL (SDXL) est une version plus récente et plus puissante de Stable Diffusion, capable de générer des images de haute qualité à des résolutions plus élevées (768x768 à 1024x1024). Il est possible de l'intégrer et de l'utiliser avec stable-diffusion-webui.
Chargement de modèles spécifiques
Pour utiliser des modèles optimisés pour des environnements spécifiques, vous pouvez remplacer le pipeline de base :
- Pour charger un modèle OpenVINO et exécuter l'inférence avec OpenVINO Runtime, remplacez StableDiffusionXLPipeline par Optimum OVStableDiffusionXLPipeline.
- Pour charger un modèle ONNX et exécuter l'inférence avec ONNX Runtime, remplacez StableDiffusionXLPipeline par Optimum ORTStableDiffusionXLPipeline.
Performance et VRAM
Le modèle de base est utilisé pour générer des latents de la taille de sortie désirée, puis le refiner est appliqué aux latents générés dans la première étape, en utilisant le même prompt.
L'utilisation de votre propre matériel avec au moins 16 Go de mémoire GPU est recommandée pour une expérience fluide. Les modèles sont destinés à des fins de recherche.
Génération d'images sans carte graphique (CPU)
Il est également possible de configurer et d'utiliser Stable Diffusion sur un serveur Linux en utilisant uniquement le CPU, sans nécessiter de carte graphique dédiée. Cette méthode, bien que plus complexe et potentiellement plus lente, permet de contourner la nécessité d'acheter du matériel supplémentaire.
La configuration sur un serveur Linux via le CPU n'a pas permis une exécution à distance de Stable Diffusion comme cela peut être le cas avec des interfaces basées sur le cloud. L'utilisateur doit être physiquement présent sur le serveur pour interagir avec l'outil.
Cette méthode a été testée avec succès sur WSL (Windows Subsystem for Linux), et des captures d'écran ont été réalisées à partir de cette configuration.
L'objectif est de s'appuyer sur l'interface graphique d'Automatic1111, en utilisant uniquement le CPU. Cette approche a été mise en œuvre en utilisant uniquement les ressources d'un ancien ordinateur.
tags: #stable #diffusion #xl #linux