Maîtriser l'API de ChatGPT : Le Guide Complet
L'intelligence artificielle et le traitement du langage naturel ont révolutionné le monde de la technologie, ouvrant la voie à des applications et services inimaginables il y a quelques années. Au cœur de cette transformation se trouve ChatGPT, un modèle de langage développé par OpenAI. Cet article vous propose une plongée détaillée dans l'API de ChatGPT, expliquant son importance pour vos applications et vous guidant pas à pas dans son intégration efficace. Que vous soyez un développeur expérimenté ou un passionné de technologie, ce guide est conçu pour vous aider à exploiter pleinement le potentiel de ce modèle révolutionnaire.
Prérequis pour l'utilisation de l'API ChatGPT
Avant de commencer, assurez-vous de disposer des outils et des connaissances nécessaires. Vous aurez besoin d'une compréhension de base en programmation, idéalement en Python, ainsi que d'un compte sur la plateforme OpenAI. Si vous n'en possédez pas encore, le processus d'inscription est simple.
Obtenir vos clés API OpenAI
La première étape cruciale pour utiliser l'API de ChatGPT est d'obtenir vos clés API auprès d'OpenAI. Rendez-vous sur le site officiel d'OpenAI, connectez-vous ou créez un compte. Une fois authentifié, accédez à la section "Personnel" en haut à droite de la page et sélectionnez "Voir les clés API". Sur la page dédiée, cliquez sur "Créer une nouvelle clé secrète". Conservez cette clé précieusement, car elle ne vous sera plus jamais affichée.
Comprendre les modèles de ChatGPT
Lors de l'utilisation de l'API, vous avez le choix entre plusieurs modèles, notamment gpt-3.5-turbo et gpt-4. Ces modèles sont le moteur des capacités de génération de texte de ChatGPT. Bien qu'optimisés pour les conversations, ils sont également performants pour la complétion de texte. Il est important de noter que GPT-4, le modèle le plus récent et le plus puissant, est actuellement soumis à une liste d'attente. Le modèle gpt-3.5-turbo est, quant à lui, accessible à tous et offre un excellent rapport qualité-prix par rapport aux modèles GPT-3 précédents.

Configuration et personnalisation de l'API ChatGPT
Configuration de base de l'API
Une fois votre clé API obtenue et votre modèle choisi, vous pouvez procéder à la configuration de base. La configuration du modèle de chat pour votre appel API peut être réalisée en utilisant Python et la bibliothèque OpenAI. L'exemple de code suivant illustre cette démarche :
import openaiopenai.api_key = "VOTRE_CLÉ_API"completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", temperature=0.8, max_tokens=2000, messages=[ {"role": "system", "content": "Vous êtes un assistant qui raconte des blagues de papa."}, {"role": "user", "content": "Racontez-moi une blague sur les mathématiques."} ])Dans cet exemple, le modèle gpt-3.5-turbo est utilisé, avec des paramètres tels que temperature et max_tokens pour contrôler le comportement du modèle. Pour des expérimentations rapides sans installation d'un environnement de développement Python, des exécuteurs de code en ligne comme Replit ou Online Python sont disponibles.
Personnalisation avancée
L'API de ChatGPT offre une grande flexibilité pour personnaliser votre expérience. Vous pouvez utiliser différents rôles dans les messages pour affiner le comportement de l'assistant. Le rôle system permet de définir le contexte général, tandis que le rôle user est utilisé pour soumettre des instructions spécifiques. Des paramètres comme la temperature (qui régule la créativité des réponses) et max_tokens (qui limite la longueur des réponses) peuvent être ajustés.
messages = [ {"role": "system", "content": "Vous êtes un assistant qui aide à coder."}, {"role": "user", "content": "Comment créer une boucle en Python ?"}]Dans cet exemple, le rôle system établit le contexte d'aide au codage, et le rôle user soumet l'instruction précise.

Applications et cas d'usage de l'API ChatGPT
Utilisation de l'API pour la complétion de texte
L'API de ChatGPT ne se limite pas aux conversations ; elle excelle également dans la complétion de texte. Cette fonctionnalité est particulièrement utile pour des applications telles que les générateurs de contenu ou les assistants à la rédaction. Voici comment configurer l'API pour une tâche de complétion de texte :
import openaiopenai.api_key = "VOTRE_CLÉ_API"completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", temperature=0.8, max_tokens=2000, messages=[ {"role": "system", "content": "Vous êtes un poète qui crée des poèmes émouvants."}, {"role": "user", "content": "Écrivez un court poème sur la solitude."} ])Ici, le rôle system définit l'identité de l'assistant comme un poète, et le rôle user lui demande de composer un poème sur la solitude.
Construire des applications avec l'API de ChatGPT
L'API de ChatGPT ouvre un large éventail de possibilités pour le développement d'applications. Qu'il s'agisse de créer un chatbot sophistiqué, un générateur de contenu marketing, ou même une application de traduction de code, les limites sont celles de votre imagination. Vous pouvez interagir directement avec l'endpoint API ou utiliser les bibliothèques Python ou Node.js fournies par OpenAI. Des bibliothèques tierces, maintenues par la communauté, sont également disponibles, bien qu'OpenAI ne garantisse pas leur sécurité.
Intégrer l'IA à ton App Facilement : Voici comment faire !
Gestion des réponses et limitations de l'API
Réponse et format de l'API
Les réponses de l'API de ChatGPT sont structurées au format JSON. Il est essentiel de savoir comment extraire les informations pertinentes pour votre application. Voici un exemple de réponse typique :
{ "choices": [ { "message": { "role": "assistant", "content": "La solitude est un océan sans fin, où l'âme se perd et se retrouve." } } ]}Dans cet exemple, la réponse de l'assistant se trouve dans le champ content de l'objet message, au sein du tableau choices.
Problèmes et limitations
Comme toute technologie avancée, l'API de ChatGPT présente des défis et des limitations. Les modèles peuvent parfois générer des réponses biaisées ou inappropriées. De plus, il existe des contraintes sur le nombre de tokens (unités de texte) que chaque modèle peut traiter. Le modèle gpt-3.5-turbo est limité à 4 096 tokens (environ 3 000 mots), tandis que le modèle gpt-4 peut gérer jusqu'à 8 192 tokens (environ 6 000 mots) dans sa version standard, et jusqu'à 32 768 tokens dans sa version étendue. Il est donc primordial de tenir compte de ces limites lors de la conception de votre application.
Exploration des modèles et des paramètres avec le Playground OpenAI
Le Playground d'OpenAI
Pour ceux qui ne sont pas familiers avec Python ou qui souhaitent expérimenter rapidement, le Playground d'OpenAI offre une interface intuitive. Il permet de tester diverses configurations sans écrire de code complexe. Vous pouvez ajuster des paramètres tels que la temperature pour moduler la créativité des réponses, ou les séquences d'arrêt pour définir quand la génération de texte doit s'interrompre. Cette flexibilité est particulièrement précieuse pour les développeurs et chercheurs qui veulent valider des concepts avant un déploiement.
Compréhension approfondie des modèles
Le Playground est également un excellent outil pour mieux cerner les capacités des modèles. En observant leurs réactions à différentes invites et configurations de paramètres, vous pouvez identifier leurs forces et faiblesses, vous aidant ainsi à choisir le modèle le plus adapté à vos besoins spécifiques.
Coût et efficacité
Enfin, le Playground peut servir de simulateur pour évaluer les coûts d'utilisation des différents modèles. Chaque modèle ayant sa propre tarification, effectuer des tests préliminaires vous permettra d'estimer le rapport coût-efficacité pour votre projet.
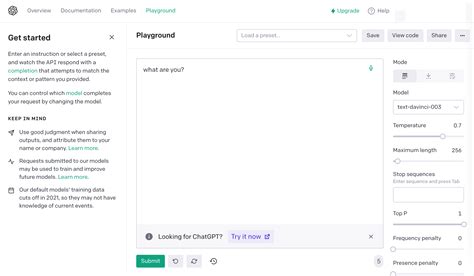
Explication détaillée des paramètres du Playground d'OpenAI
Température
La temperature contrôle le degré de créativité et de variabilité des réponses. Une valeur proche de 1 génère des réponses plus aléatoires et créatives, tandis qu'une valeur proche de 0 produit des réponses plus déterministes et focalisées sur le texte le plus probable.
- Valeur élevée (proche de 1) : Réponses plus créatives, mais potentiellement moins cohérentes.
- Valeur basse (proche de 0) : Réponses plus prévisibles et centrées sur le texte le plus probable.
Top P (Probabilité de seuil)
Le paramètre Top P ajuste la diversité des réponses en excluant les tokens dont la probabilité cumulée est inférieure à un seuil défini. Cela permet d'éviter des réponses inattendues ou incohérentes.
- Valeur élevée : Plus de diversité dans les réponses, mais risque accru d'incohérence.
- Valeur basse : Réponses plus concentrées et prévisibles.
Longueur maximale et séquences d'arrêt
La longueur maximale définit le nombre de tokens que le modèle peut générer. Les séquences d'arrêt sont des chaînes de caractères qui indiquent au modèle où cesser la génération de texte.
- Longueur maximale : Contrôle la longueur de la sortie.
- Séquences d'arrêt : Indique au modèle où terminer la réponse.
Pénalité de fréquence et pénalité de présence
Ces paramètres permettent de personnaliser l'originalité et la diversité de la sortie. La pénalité de fréquence réduit la probabilité des tokens récurrents, tandis que la pénalité de présence augmente la probabilité des tokens inédits.
- Pénalité de fréquence : Réduit la redondance dans les réponses.
- Pénalité de présence : Encourage la diversité et l'originalité des réponses.
La maîtrise de ces paramètres est essentielle pour obtenir des résultats optimaux et adaptés à vos besoins spécifiques.
Tarification du Playground d'OpenAI
La tarification varie selon les modèles :
- Modèle GPT-4 : Le prix par 1000 tokens est de $0,03 pour les invites et $0,06 pour les complétions avec un contexte de 8K ; $0,06 et $0,12 respectivement pour un contexte de 32K.
- Modèle ChatGPT (gpt-3.5-turbo) : Le prix est de $0,002 par 1000 tokens.
- Modèle InstructGPT : Les prix varient de $0,0004 (modèle Ada) à $0,0200 (modèle Davinci) par 1000 tokens.
- Modèles Fine-tuned : Le coût dépend du volume de tokens utilisés pour l'entraînement et l'inférence.
Historique et évolution des modèles de langage OpenAI
L'utilisation de l'API GPT-3, notamment avec text-davinci-002 en mars 2022, a marqué une étape importante. Ce modèle, le plus avancé de la série GPT-3, offrait une polyvalence remarquable pour le texte, le code et la structuration stratégique. L'arrivée de ChatGPT a démocratisé l'accès à ces technologies, passant d'un usage principalement technique via API à une accessibilité grand public. Cette évolution a nécessité une sensibilisation accrue aux cas d'usage et aux implications profondes pour les individus, les équipes et les organisations.
La transformation s'opère à tous les niveaux :
- AI Organization : Des entreprises comme Block ont réduit leurs effectifs, attribuant cette efficacité accrue à l'intégration d'outils d'IA qui permettent à des équipes plus restreintes d'atteindre des objectifs plus ambitieux.
- AI Nation : Des tensions émergent, comme le refus d'Anthropic d'assouplir certaines restrictions sur l'usage de ses modèles par le gouvernement, notamment pour la surveillance de masse ou les armes autonomes.
L'évolution est rapide : les métiers se transforment, certains disparaissent, d'autres apparaissent, les organisations se redéfinissent, et les nations intègrent l'IA dans leurs stratégies de puissance et de gouvernance. L'impact de l'IA n'est plus théorique ; il s'agit d'une réalité tangible qui redessine notre monde.
Pourquoi est-il important de comprendre les modèles de langage d'OpenAI ?
Si vous envisagez d'implémenter l'API d'OpenAI à l'échelle de votre entreprise, la facture peut rapidement s'avérer conséquente. Derrière le succès de ChatGPT se cache une gamme de modèles aux capacités, spécificités et tarifs variés. L'objectif est d'utiliser le modèle le plus adapté à vos besoins pour optimiser votre investissement.
À titre d'analogie, utiliser une voiture de sport ultra-performante pour des trajets urbains limités en vitesse est peu rentable. Il est préférable d'opter pour un véhicule plus économique qui remplit la même fonction de manière plus efficiente. ChatGPT, souvent associé à GPT-4, représente la "voiture de sport" avec toutes les options, potentiellement trop coûteuse pour de nombreuses entreprises.
Les modèles d'OpenAI : un aperçu
L'API d'OpenAI s'appuie sur un ensemble diversifié de modèles, chacun possédant des caractéristiques distinctes.
Pour cet article, l'analyse s'est appuyée sur les modèles disponibles dans le Playground d'OpenAI, notamment les séries GPT-3 et Codex.
Modèles GPT-3 :
- text-davinci-003 : Modèle GPT-3 puissant, sorti en juin 2020, avec 175 milliards de paramètres. Il excelle dans diverses tâches de traitement du langage naturel comme la complétion de texte, la réponse aux questions et la traduction.
- text-curie-001 : Modèle GPT-3 efficace avec 6,7 milliards de paramètres, conçu pour être plus performant que les modèles plus grands.
- text-babbage-001 : Modèle GPT-3 avec 1,2 milliard de paramètres, capable de réaliser diverses tâches de traitement du langage naturel.
- text-ada-001 : Modèle GPT-3 avec 0,125 milliard de paramètres, adapté aux tâches de traitement du langage naturel de base.
- text-davinci-002 : Deuxième version du modèle Davinci, sortie en juillet 2021, avec 6 milliards de paramètres. Il s'agit d'une version allégée de text-davinci-003.
- text-davinci-001 : Première version du modèle Davinci, sortie en juin 2020, avec 13 milliards de paramètres. Prédécesseur de text-davinci-003.
- davinci-instruct-beta : Modèle GPT-3 conçu pour les tâches de traitement du langage naturel basées sur des instructions, avec 2,7 milliards de paramètres. Idéal pour les chatbots et assistants vocaux.
- davinci : Modèle Davinci original, sorti en juin 2020, avec 13 milliards de paramètres.
- curie-instruct-beta : Modèle GPT-3 pour les tâches basées sur des instructions, avec 92 millions de paramètres.
- curie : Modèle GPT-3 avec 2,7 milliards de paramètres, nommé d'après Marie Curie, conçu pour la complétion et la résumé de texte.
- babbage : Modèle GPT-3 avec 125 millions de paramètres, nommé d'après Charles Babbage, adapté à la complétion et au résumé de texte.
- ada : Modèle GPT-3 avec 40 millions de paramètres, nommé d'après Ada Lovelace, pour des tâches de traitement du langage naturel.
Modèles Codex :
- code-davinci-002 : Version de Codex, système basé sur GPT-3 qui génère du code à partir de descriptions en langage naturel. Sorti en août 2021, il possède 14,8 milliards de paramètres et est destiné au développement logiciel, générant du code dans plusieurs langages.
- code-cushman-001 : Autre version de Codex, sortie en juin 2021, avec 2,5 milliards de paramètres. Également conçu pour générer du code à partir de descriptions en langage naturel.
Chaque modèle linguistique possède ses propres capacités, avec des nombres de paramètres variés et des cas d'usage spécifiques. Par exemple, Codex est privilégié pour les tâches liées au code, tandis que GPT est plus adapté aux usages mixtes. La limite en tokens de chaque modèle, c'est-à-dire sa capacité à analyser une invite et à générer une réponse, est également un facteur déterminant. Enfin, la facturation étant basée sur les tokens consommés, une bonne maîtrise de cet aspect est cruciale.
Méthodologie de comparaison des modèles
Pour évaluer les différences, la même invite a été soumise à chaque modèle avec des paramètres strictement identiques. Cette étude ne prétend pas révéler la vérité absolue sur les capacités de chaque modèle, car une analyse plus approfondie avec des invites complexes serait nécessaire. Néanmoins, les invites relativement simples utilisées ici suffisent à mettre en évidence les limites de chaque modèle.
Exemples d'invites et leurs résultats
Invite 1 - Génération de code :
> write javascript hello world function
Les résultats varient, certains modèles produisant une fonction JavaScript complète, d'autres des fragments de code ou des explications textuelles.
Invite 2 - Traduction :
> translate "Hello, how are you doing ?" to French
La plupart des modèles parviennent à traduire la phrase correctement en "Bonjour, comment allez-vous ?", bien que certaines variantes existent.
Invite 3 - Fait historique :
> When happened the world war 2 ?
Cette invite teste la capacité et la connaissance des modèles sur un événement historique majeur. Les réponses varient en précision et en détail.
Paramètres utilisés pour la comparaison
Les paramètres par défaut du Playground OpenAI ont été utilisés pour chaque appel API :
- Mode : Complete
- Temperature : 0
- Longueur maximale : 256
- Séquences d'arrêt : vide
- Top P : 1
- Pénalité de fréquence : 0
- Best of : 1
tags: #text #davinci #003 #api