Machines à Vecteurs de Support (SVM) : Classification et Régression
Les Machines à Vecteurs de Support (SVM), ou Support Vector Machines en anglais, constituent un algorithme d'apprentissage automatique supervisé puissant, largement utilisé pour résoudre des problèmes de classification et de régression. Cet outil est particulièrement apprécié pour sa précision dans les tâches de classification, permettant d'interpréter des données complexes et de prendre des décisions automatisées.
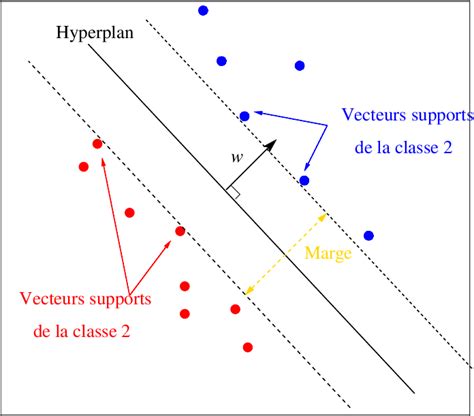
Principe Fondamental des SVM
L'objectif principal d'un SVM est de trouver la meilleure frontière de décision, appelée hyperplan, qui sépare efficacement les points de données appartenant à différentes classes. Dans un espace à deux dimensions, cet hyperplan peut être une ligne ; dans un espace à trois dimensions, un plan ; et dans des dimensions supérieures, un sous-espace à (n-1) dimensions. L'astuce réside dans la maximisation de la marge, c'est-à-dire la distance entre l'hyperplan et les points de données les plus proches de chaque classe. Ces points de données critiques, situés aux limites de la marge et les plus proches de l'hyperplan, sont appelés vecteurs de support.
En maximisant cette marge, le modèle SVM assure une meilleure généralisation aux nouvelles données, réduisant ainsi le risque de surapprentissage. Les SVM ont été développées dans les années 1990, basées sur les considérations théoriques de Vladimir Vapnik concernant la théorie statistique de l'apprentissage.
Fonctionnement des SVM
Le processus de fonctionnement d'un SVM peut être décomposé en plusieurs étapes clés :
- Collecte et Étiquetage des Données : Dans un premier temps, les données d'entraînement sont collectées et chaque exemple de données est correctement étiqueté pour indiquer sa classe respective.
- Transformation des Données (Kernel Trick) : Les SVM excellent dans la gestion des données qui ne sont pas linéairement séparables. Pour ce faire, ils utilisent l'astuce du noyau (kernel trick). Cette technique transforme implicitement les données d'entrée d'un espace de faible dimension vers un espace de caractéristiques de dimension supérieure, où une séparation linéaire devient possible. L'avantage majeur est que cette transformation n'a pas besoin d'être calculée explicitement ; seule la fonction noyau, qui calcule le produit scalaire dans l'espace transformé, est nécessaire.
- Optimisation de l'Hyperplan : Une fois les données dans un espace approprié (potentiellement de dimension supérieure), le SVM résout un problème d'optimisation convexe pour trouver l'hyperplan optimal. Cet hyperplan maximise la marge tout en minimisant les erreurs de classification.
- Classification ou Régression : Après l'entraînement, le modèle SVM peut classer de nouveaux points de données en déterminant de quel côté de la frontière de décision ils se situent, ou prédire une valeur continue dans le cas de la régression.
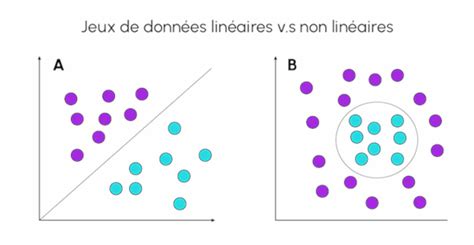
Variantes des SVM
Les SVM se déclinent en plusieurs variantes, adaptées à différents types de problèmes :
SVM Linéaires
Les SVM linéaires utilisent une limite de décision linéaire (une droite ou un hyperplan) pour séparer les classes. Ils sont particulièrement efficaces lorsque les données sont linéairement séparables, c'est-à-dire qu'une simple frontière droite peut diviser les classes. Ces modèles sont efficaces en termes de calcul et faciles à interpréter.
SVM Non Linéaires
Lorsque les données ne sont pas linéairement séparables dans leur espace d'origine, les SVM non linéaires entrent en jeu. Ils utilisent des fonctions de noyau (kernels) pour mapper implicitement les données dans un espace de caractéristiques de plus haute dimension, où une séparation linéaire peut être trouvée. Les noyaux les plus couramment utilisés incluent :
- Noyau Linéaire : Simple et rapide, utile lorsque les données sont déjà presque séparables linéairement.
- Noyau Polynomial : Plus puissant que le noyau linéaire, capable de modéliser des relations non linéaires.
- Noyau RBF (Radial Basis Function) : Très répandu et efficace pour une large gamme de problèmes de classification, il est particulièrement adapté aux données complexes.
- Noyau Sigmoïde : Similaire au RBF mais avec une forme différente, peut être utile pour certains problèmes spécifiques.
Le choix de la fonction noyau est crucial et dépend des caractéristiques des données, impliquant un compromis entre précision et complexité de calcul.
Régression Vectorielle de Support (SVR)
La Régression Vectorielle de Support (SVR) est une extension des SVM appliquée aux problèmes de régression. Au lieu de trouver une frontière qui sépare les classes, le SVR vise à trouver une fonction qui modélise la relation entre les caractéristiques d'entrée et les valeurs de sortie continues. Comme les SVM, le SVR utilise le concept de marges pour définir une plage d'erreur acceptable et peut traiter des données linéaires et non linéaires grâce à différents types de noyaux.
SVM Multi-classes
Les SVM sont fondamentalement des classificateurs binaires. Pour gérer des problèmes avec plus de deux classes, plusieurs stratégies sont employées :
- One-vs-All (OvA) : Un classifieur binaire est entraîné pour chaque classe, distinguant cette classe de toutes les autres.
- One-vs-One (OvO) : Un classifieur binaire est entraîné pour chaque paire de classes. Lors de la prédiction, un vote majoritaire détermine la classe finale.
Avantages des SVM
Les Machines à Vecteurs de Support offrent plusieurs avantages significatifs :
- Efficacité dans les Espaces à Haute Dimension : Ils sont performants même lorsque le nombre de caractéristiques est supérieur au nombre d'échantillons.
- Résistance à l'Overfitting : Le principe de maximisation de la marge permet une bonne généralisation et réduit le risque de surajustement.
- Polyvalence : Ils peuvent être appliqués à des problèmes de classification et de régression, et s'adaptent à des relations complexes grâce aux fonctions noyau.
- Efficacité avec des Données Limitées : Ils peuvent donner de bons résultats même avec des ensembles de données d'apprentissage restreints, en se concentrant sur les vecteurs de support.
- Capacité à Traiter des Données Non Linéaires : L'astuce du noyau permet de gérer efficacement les données non séparables linéairement.
- Mémoire Efficace : L'utilisation des vecteurs de support dans la fonction de décision réduit la charge de calcul.
- Moins Sensibles au Bruit : Ils sont moins affectés par les valeurs aberrantes par rapport à d'autres classificateurs.
Limites et Défis des SVM
Malgré leurs forces, les SVM présentent également certaines limitations :
- Intensité de Calcul : L'entraînement peut être coûteux en temps et en ressources, surtout avec de grands ensembles de données.
- Sensibilité à l'Ajustement des Paramètres : Les performances dépendent fortement du choix des hyperparamètres (comme C et le type de noyau), nécessitant une optimisation minutieuse.
- Absence de Résultats Probabilistes : Les SVM ne fournissent pas directement de probabilités de classe, nécessitant des techniques supplémentaires pour cette estimation.
- Difficulté d'Interprétation des Modèles Complexes : Les modèles utilisant des noyaux non linéaires peuvent être difficiles à interpréter ("boîte noire").
- Problèmes d'Évolutivité : L'entraînement sur des ensembles de données extrêmement volumineux peut devenir impraticable.
- Choix du Noyau : Sélectionner le bon noyau et ses paramètres peut être un processus complexe.
Domaines d'Application des SVM
Les SVM sont largement appliqués dans divers domaines en raison de leur polyvalence et de leur précision :
- Reconnaissance de Formes et Vision par Ordinateur : Reconnaissance d'objets, détection de visages, segmentation d'images.
- Traitement du Langage Naturel (NLP) : Classification de texte, analyse de sentiments, catégorisation de documents.
- Bioinformatique : Prédiction de la structure des protéines, classification de gènes, détection de motifs biologiques.
- Finance : Prévision de séries temporelles, détection de fraude, modélisation du risque.
- Marketing et E-commerce : Recommandation de produits, segmentation de marché, analyse des comportements clients.
- Diagnostic Médical : Prédiction de maladies, analyse de données médicales.
- Industrie et Ingénierie : Contrôle qualité, maintenance prédictive, optimisation de processus.
Tout savoir sur le Support Vector Machine (SVM) - LES MODELES LINEAIRES #16
Mise en Œuvre Pratique (Exemples avec Python)
L'implémentation des SVM peut être réalisée à l'aide de bibliothèques comme Scikit-learn en Python.
Exemple de Classification
Pour la classification, on utilise généralement la classe SVC (Support Vector Classifier).
import numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.svm import SVCfrom sklearn.datasets import make_classificationfrom sklearn.metrics import accuracy_score# Génération de données synthétiquesX, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)# Division des données en ensembles d'entraînement et de testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Création et entraînement du modèle SVM avec un noyau linéairesvm_model = SVC(kernel='linear', random_state=42)svm_model.fit(X_train, y_train)# Prédiction et calcul de la précisiony_pred = svm_model.predict(X_test)accuracy = accuracy_score(y_test, y_pred)print(f"Précision du modèle SVM : {accuracy:.2f}")Exemple de Régression
Pour la régression, on utilise la classe SVR (Support Vector Regressor).
import numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.svm import SVRfrom sklearn.datasets import make_regressionfrom sklearn.metrics import mean_squared_error# Génération de données synthétiquesX, y = make_regression(n_samples=1000, n_features=20, noise=0.1, random_state=42)# Division des données en ensembles d'entraînement et de testX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Création et entraînement du modèle SVR avec un noyau RBFsvm_model = SVR(kernel='rbf')svm_model.fit(X_train, y_train)# Prédiction et calcul du RMSEy_pred = svm_model.predict(X_test)rmse = np.sqrt(mean_squared_error(y_test, y_pred))print(f"RMSE du modèle SVM : {rmse:.2f}")tags: #vectorisation #par #machine #a #vecteurs #de