La Vectorisation : Optimisation des Performances par le Traitement Parallèle des Données
La vectorisation est un processus fondamental dans l'optimisation des performances informatiques, consistant à transformer un algorithme conçu pour opérer sur une seule donnée à la fois (implémentation scalaire) en une implémentation qui traite plusieurs paires d'opérandes simultanément (implémentation vectorielle). Cette approche tire parti des capacités des processeurs modernes qui intègrent des instructions SIMD (Single Instruction Multiple Data). Ces instructions permettent d'appliquer la même opération à plusieurs éléments de données en parallèle, réduisant ainsi considérablement le temps d'exécution des tâches répétitives.

Les Fondements de la Vectorisation : Instructions SIMD et Registres
Au cœur de la vectorisation se trouvent les instructions SIMD. Plutôt que d'exécuter une seule opération sur une seule donnée par cycle d'horloge, comme dans une architecture scalaire classique, les instructions SIMD permettent de réaliser la même opération sur un ensemble de données (un vecteur) en un seul cycle. Les processeurs modernes sont équipés de différentes familles d'instructions SIMD, offrant des capacités de traitement de données toujours plus larges.
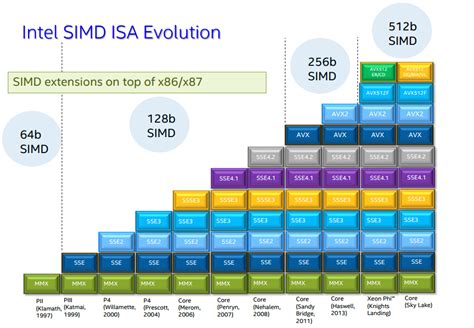
Les Familles d'Instructions SIMD
- SSE (Streaming SIMD Extensions) : Il s'agit de l'une des familles les plus communes. Les registres SSE, d'une taille de 128 bits, permettent de traiter par exemple 4 nombres flottants (float) à la fois. Les manipulations de nombres flottants sont généralement plus optimisées avec ces instructions, même sans appliquer de vectorisation spécifique.
- AVX (Advanced Vector Extensions) : Cette famille d'instructions, disponible sur les processeurs plus récents, offre des registres de 256 bits (AVX) et même 512 bits (AVX-512). Ces registres permettent de manipuler respectivement 8 ou 16 nombres flottants simultanément, offrant un gain de performance significatif.
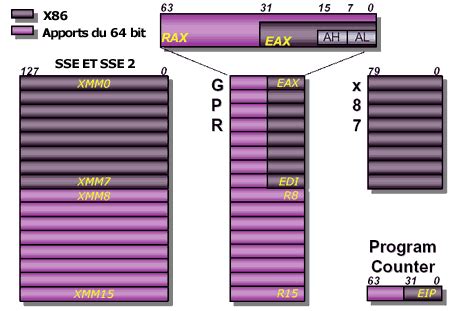
Principes et Caractéristiques des Processeurs Vectoriels
Les processeurs vectoriels sont spécifiquement conçus pour traiter efficacement de grands volumes de données organisées en tableaux ou en vecteurs. Contrairement aux architectures scalaires qui traitent les données élément par élément, les processeurs vectoriels agissent sur des blocs entiers de données de manière synchrone. Leur architecture repose sur des registres vectoriels de grande taille, capables de stocker des suites d'éléments traités collectivement par des instructions vectorielles.
Le paradigme SIMD (Single Instruction Multiple Data) est fondamental : une seule instruction exécute la même opération sur plusieurs éléments de données en parallèle. Par exemple, une instruction d'addition vectorielle réalise une addition élément par élément sur plusieurs paires de valeurs issues de deux vecteurs en une seule opération.
Cette approche offre des avantages considérables en termes de performances, particulièrement pour les applications de calcul scientifique, de simulation numérique, de traitement d'images et du signal, où les opérations répétitives et massivement parallélisables sont courantes. La gestion efficace des flux mémoire est également cruciale pour alimenter rapidement les registres vectoriels et éviter les goulets d'étranglement.
Fonctionnement Technique et Différences avec les Architectures Scalaires
Le mode de fonctionnement d'un processeur vectoriel implique une organisation matérielle où les données sont représentées en séquences (vecteurs). Les instructions vectorielles dictent des opérations appliquées simultanément à tous les éléments du registre vectoriel concerné. Les débits de données requis sont bien supérieurs à ceux d'un processeur classique, nécessitant des mécanismes sophistiqués de préchargement et de distribution mémoire.
À l'inverse de l'architecture scalaire qui opère sur une donnée unique par instruction, le processeur vectoriel maximise le parallélisme en réduisant le nombre d'instructions pour une tâche donnée. Ce modèle est particulièrement avantageux pour les opérations répétitives comme les multiplications de matrices ou les transformations géométriques.
La programmation pour processeurs vectoriels demande une approche algorithmique axée sur la vectorisation des tâches. Cela implique souvent une réorganisation des calculs en lots compacts et alignés sur les registres vectoriels, ainsi qu'une optimisation de la gestion des accès mémoire pour minimiser la latence.
Gestion des Boucles et Branchements
Les processeurs vectoriels excellent dans le traitement séquentiel et sans interruption. Cependant, leurs performances peuvent être impactées par de fréquents branchements conditionnels ou des opérations non vectorisables. L'exploitation optimale de ces processeurs requiert donc une adaptation logicielle et une anticipation des particularités matérielles.
Pour gérer les boucles, des techniques comme le déroulage de boucles sont utilisées. Elles visent à réduire le nombre d'itérations en dupliquant le corps de la boucle. Dans le contexte SIMD, cela permet de regrouper plusieurs itérations scalaires en une seule instruction vectorielle, à condition que les éléments du tableau soient traités indépendamment ou d'une manière suffisamment simple.
Lorsque le nombre d'éléments d'un tableau n'est pas un multiple exact de la taille du vecteur (par exemple, 4 éléments pour une instruction traitant 4 flottants), les compilateurs utilisent généralement deux boucles : une pour les éléments traités par instructions SIMD, et une autre pour les éléments restants avec des instructions non vectorielles.
La présence de branchements conditionnels dans les boucles à vectoriser pose un défi : certaines instructions peuvent devoir s'appliquer à certains éléments et pas à d'autres. Pour gérer cela, les processeurs vectoriels peuvent utiliser des registres spécifiques comme le Vector Mask Register. Ce registre stocke un bit pour chaque élément du vecteur, indiquant si l'instruction doit s'exécuter sur la donnée associée. Cela permet de sélectionner quelles données traiter, évitant ainsi l'exécution inutile d'instructions.
Optimisation du Code Vectorisé
L'optimisation du code vectorisé est essentielle pour exploiter pleinement le potentiel des processeurs. Plusieurs facteurs peuvent influencer la capacité d'un compilateur à générer du code vectorisé efficace.
- Aliasing des pointeurs : Le possible aliasing des pointeurs, où plusieurs pointeurs peuvent référencer la même zone mémoire, peut nuire gravement à la vectorisation. Dans le meilleur des cas, le compilateur génère une boucle vectorisée et une boucle non vectorisée, avec un test pour sélectionner la boucle appropriée. Dans le pire des cas, le code n'est tout simplement pas vectorisé.
- Alignement en mémoire : L'alignement des données manipulées en mémoire peut considérablement accélérer leur chargement. Cet alignement dépend de la taille des registres SIMD souhaités.
- Organisation du code : Les gains de performance les plus significatifs proviennent souvent de l'organisation du code qui permet au compilateur de vectoriser automatiquement. Par exemple, le pattern Arrays of Structures versus Structures of Arrays peut nécessiter une modification du design du programme pour améliorer la vectorisation.
Des outils comme l'Intel C++ Compiler (ICC) sont reconnus pour leur efficacité dans l'optimisation du code, notamment en matière de vectorisation. Parfois, au lieu de suggérer des instructions au compilateur, il peut être plus efficace d'utiliser directement des intrinsèques ou d'écrire du code en assembleur (par exemple, avec `__asm`).
Il est important de noter que le passage d'instructions AVX à SSE (ou inversement) peut nécessiter au compilateur de changer de mode, ce qui peut entraîner une perte de cycles d'horloge selon le processeur.
Historique, Évolution et Domaines d'Application
L'émergence des processeurs vectoriels remonte aux années 1970, avec des machines emblématiques comme le Cray-1. Ces superordinateurs utilisaient des processeurs vectoriels pour traiter de vastes ensembles de données matricielles dans des domaines tels que la météorologie, la simulation physique, ou l'analyse structurale.
Au fil des décennies, l'architecture vectorielle est devenue un pilier des supercalculateurs, inspirant l'introduction d'unités de calcul spécialisées dans les architectures contemporaines, comme les unités SIMD dans les processeurs grand public (par exemple, AltiVec, MMX, SSE, AVX).
Bien que le développement d'architectures vectorielles dédiées ait été moins prédominant face à l'essor du calcul parallèle massif et des GPUs, l'influence des concepts vectoriels reste palpable. Les processeurs vectoriels sont toujours utilisés pour des tâches spécifiques, nécessitant une optimisation logicielle adaptée.
Domaines d'Application Actuels
- Calcul Scientifique et Ingénierie : Simulation numérique, modélisation complexe, analyse de données massives.
- Traitement d'Images et Vidéo : Rendu 3D, traitement massivement parallèle d'images, compression/décompression audio/vidéo.
- Intelligence Artificielle et Machine Learning : Les algorithmes de Deep Learning exploitent intensivement les calculs linéaires sur de grands ensembles de données, renouant avec la logique du processeur vectoriel.
- Analyse de Signaux : Traitement de signaux biomédicaux, analyse acoustique.
Vectorisation dans le Contexte de l'Intelligence Artificielle
La vectorisation est un processus essentiel en intelligence artificielle, consistant à convertir des données brutes (texte, images, audio) en vecteurs numériques. Ces représentations mathématiques permettent aux algorithmes d'apprentissage automatique de manipuler, comparer et apprendre à partir de l'information, car les modèles d'IA ne traitent que des nombres.
Méthodes de Vectorisation
- Traitement du Langage Naturel (NLP) :
- Méthodes simples : One-hot encoding.
- Approches plus sophistiquées : Word2Vec, GloVe, BERT (embeddings contextuels).
- Pour les phrases : Sentence-BERT.
- Vision par Ordinateur :
- Extraction de caractéristiques : HOG, SIFT, ORB.
- Réseaux de neurones convolutifs (CNN) : AlexNet, ResNet.
- Architectures basées sur les Transformers : Vision Transformers (ViT).
- Modèles multimodaux : CLIP (joint texte et image).
- Audio :
- Représentations temps-fréquence : Spectrogramme, Mel-Spectrogramme.
- Features audio : MFCC.
- Modèles pré-entraînés : Wav2Vec 2.0, HuBERT, Whisper.
- Données Structurées : Tables SQL, CSV, Excel.
- Données Semi-structurées : JSON, logs, XML.
- Données Non Structurées : Représentent une grande partie des données d'entreprise, mais sont plus complexes à vectoriser.
La concaténation simple de vecteurs issus de différentes modalités est souvent une approche efficace en pratique. L'utilisation de modèles pré-entraînés est courante et permet d'obtenir de bonnes performances, sauf dans des cas très spécifiques (langues rares, contraintes de sécurité extrêmes).
Enjeux et Limites de la Vectorisation en IA
- Perte d'information : La méthode de vectorisation choisie peut entraîner une perte de détails fins ou une amplification de certaines informations.
- Taille des vecteurs : Un équilibre doit être trouvé entre la simplification des données (vecteurs trop petits) et la complexité computationnelle (vecteurs trop grands).
- Coût computationnel : La vectorisation peut être coûteuse, nécessitant des optimisations au niveau matériel (GPUs) et logiciel (quantization, fusion d'opérateurs).
Perspectives et Intégration des Concepts Vectoriels dans l'Informatique Moderne
L'influence du processeur vectoriel se manifeste aujourd'hui par l'intégration croissante des capacités SIMD et l'ajout de registres vectoriels dans de nombreux processeurs généralistes. Les extensions matérielles comme SSE, AVX, et NEON (pour ARM) en sont des exemples directs.
Les architectures hybrides, combinant calcul vectoriel, processeurs scalaires et accélérateurs GPU, sont de plus en plus courantes pour répondre à l'explosion des volumes de données.
La recherche actuelle, comme le projet ANR « Shannon meets Cray », vise à surmonter les obstacles restants à la vectorisation, notamment pour des programmes complexes ou des architectures spécifiques comme RISC-V. L'objectif est de développer des logiciels capables de traiter efficacement et de manière moins énergivore les données générées par les domaines d'activité modernes.
La vectorisation, bien qu'héritée des supercalculateurs des années 1970, continue d'évoluer et de s'adapter, jouant un rôle clé dans l'optimisation des performances des systèmes informatiques, des supercalculateurs aux appareils grand public.
tags: #cpu #vectorisation #sketch