DALL-E 2 vs Stable Diffusion : Comparaison des modèles de génération d'images par IA
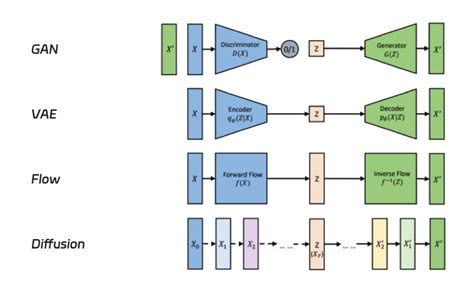
Les modèles de diffusion constituent une avancée majeure dans le domaine de la génération d'images par intelligence artificielle, surpassant même les réseaux antagonistes génératifs (GANs) dans la création d'images réalistes. Parmi les modèles les plus performants, on retrouve Stable Diffusion, DALL-E 2 d'OpenAI et Imagen de Google. Bien que leurs résultats puissent sembler similaires, ils présentent des différences notables qui les rendent uniques.
Comprendre les modèles de diffusion
Le principe fondamental des modèles de diffusion repose sur un processus itératif d'élimination progressive du bruit. Initialement, les données sont progressivement exposées à du bruit (processus de diffusion avant), puis un modèle d'apprentissage automatique est entraîné à inverser ce processus en retirant le bruit étape par étape pour obtenir une image finale nette (processus de diffusion inverse ou de débruitage paramétré).
Le processus de diffusion avant
Le processus de diffusion avant transforme les données en bruit en perturbant graduellement l'échantillon d'entrée. Formellement, il s'agit d'un processus stochastique simple qui part d'un échantillon de données et génère itérativement des échantillons de plus en plus bruités à l'aide d'un noyau de diffusion gaussien.
Le processus de débruitage inversé
Le processus de débruitage inversé annule la diffusion avant en effectuant un débruitage itératif. C'est cette capacité à inverser le processus de diffusion qui permet de générer des images à partir de bruit.
Architecture de Stable Diffusion
Pour permettre un entraînement sur des ressources limitées tout en conservant qualité et flexibilité, les créateurs de Stable Diffusion ont adopté une approche architecturale spécifique. Stable Diffusion utilise un autoencodeur avec un facteur de réduction de 8.
1. L'Autoencodeur
L'entrée du modèle est un bruit aléatoire de la taille de la sortie désirée. L'autoencodeur réduit d'abord cet échantillon à un espace latent de dimension inférieure. Pour cela, l'architecture VAE (Variational Autoencoder), composée d'un encodeur et d'un décodeur, est utilisée. L'encodeur convertit l'échantillon en une représentation latente de dimension inférieure durant l'entraînement, qui est ensuite transmise au bloc suivant.
2. Le bloc U-Net
Le bloc U-Net, intégrant des blocs ResNet, reçoit l'échantillon bruité dans l'espace latent de faible dimension, le compresse, puis le décode en le débarrassant progressivement du bruit.
3. L'Encodeur de Texte
L'encodeur de texte est chargé du traitement du langage naturel, transformant la requête (prompt) en un espace d'intégration (embedding space).
Entraînement et versions de Stable Diffusion
Stable Diffusion v1 a été pré-entraîné sur des images de 256x256 pixels, puis affiné sur des images de 512x512 pixels, toutes issues d'un sous-ensemble de la base de données LAION-5B. Le modèle utilise un autoencodeur avec un facteur de réduction de 8, un UNet de 860 millions de paramètres et un encodeur de texte CLIP ViT-L/14.
Versions et données d'entraînement :
- sd-v1-1.ckpt : 237 000 étapes à une résolution de 256x256 sur la base de données laion2B-en.
- sd-v1-2.ckpt : Reprise de sd-v1-1.ckpt. 515 000 étapes à une résolution de 512x512 sur la base de données laion-aesthetics v2 5+ (un sous-ensemble de laion2B-en avec un score esthétique estimé supérieur à 5.0, filtré pour les images d'origine de taille >= 512x512 et une probabilité de filigrane inférieure à 0.5).
- sd-v1-3.ckpt : Reprise de sd-v1-2.ckpt.
- sd-v1-4.ckpt : Reprise de sd-v1-2.ckpt.
Comparaison des performances : DALL-E 2 vs Stable Diffusion
Pour évaluer la qualité des images générées par les modèles d'IA, la métrique Fréchet Inception Distance (FID) est couramment utilisée. Le FID calcule la distance entre les vecteurs de caractéristiques d'images réelles et générées.
L'équipe de Stable Diffusion n'a pas publié de scores de référence permettant une comparaison directe avec d'autres modèles. Cependant, l'évaluation qualitative des performances des modèles de génération d'images texte-vers-image reste un atout majeur.
Analyse qualitative des résultats :
Il est possible de constater que DALL-E 2 parvient à mieux comprendre et à produire des images plus fidèles aux requêtes (prompts), tandis que Stable Diffusion peut parfois rencontrer des difficultés. Par exemple, une requête pour un chien avec une queue pourrait résulter en un chien debout sur un poisson.
Cependant, il est essentiel de comparer "les pommes aux pommes" pour une évaluation juste. Stable Diffusion a suscité un vif débat depuis sa courte existence. Contrairement à DALL-E 2, Stable Diffusion impose très peu de contraintes sur le contenu qu'il peut générer, ce qui en fait l'un des projets open-source les plus prometteurs dans le domaine de la génération d'images.
Il offre des résultats de pointe et une amélioration significative par rapport aux modèles texte-vers-image open-source précédents.
Comparatif étendu : Midjourney, DALL-E 2 et Stable Diffusion
Trois grands modèles d'IA génératrices d'images se sont imposés ces derniers mois : Midjourney, DALL-E 2 et Stable Diffusion. Ce comparatif vise à évaluer leur état de développement respectif à l'été 2023.
Il est important de noter que DALL-E 2 et Stable Diffusion étant open-source, ils peuvent être retrouvés sur différents sites ou intégrés dans d'autres outils, parfois dans des versions légèrement différentes.
Méthodologie de comparaison :
Pour comparer ces outils, plusieurs types de créations ont été testés en utilisant le même prompt, potentiellement adapté pour tenir compte de la flexibilité de chaque outil, mais en conservant systématiquement les mêmes consignes. Les prompts ont été rédigés en anglais, car tous les outils ne sont pas disponibles en français ou ne le maîtrisent pas avec la même aisance.
1. Test de photo-réalisme
Générer des visages ou des mains d'un réalisme confondant est un défi pour les IA. Le prompt utilisé était : "A realistic photo of a young happy couple".
- Midjourney : "A realistic photo of a young happy couple"
- DALL-E 2 : "A realistic photo of a young happy couple"
- DALL-E 2 via NightCafe : "A realistic photo of a young happy couple"
- DALL-E via Bing Image Creator : "A realistic photo of a young happy couple"
- Stable Diffusion 2.1 (site officiel) : "A realistic photo of a young happy couple"
- Stable Diffusion 2.1 via NightCafe : "A realistic photo of a young happy couple"
Constat : Midjourney se distingue par sa capacité à générer des images photo-réalistes d'êtres humains, là où DALL-E 2 et Stable Diffusion montrent des imperfections, se situant à la frontière de la "vallée de l'étrange".
2. Test de style artistique : Impressionnisme
Le prompt était : "An impressionist painting of a football game".
- Midjourney : "An impressionist painting of a football game"
- DALL-E 2 : "An impressionist painting of a football game"
- DALL-E 2 via NightCafe : "An impressionist painting of a football game"
- DALL-E via Bing Image Creator : "An impressionist painting of a football game"
- Stable Diffusion 2.1 : "An impressionist painting of a football game"
- Stable Diffusion 2.1 via NightCafe : "An impressionist painting of a football game"
Constat : Midjourney démontre des performances intéressantes pour imiter ou s'inspirer d'un courant artistique, en y ajoutant une touche créative.
3. Test d'imitation d'artiste : Style Hokusai
Le prompt était : "A landscape, Hokusai art style".
- Midjourney : "A landscape, Hokusai art style"
- DALL-E 2 : "A landscape, Hokusai art style"
- DALL-E 2, via NightCafe : "A landscape, Hokusai art style"
- DALL-E via Bing Image Creator : "A landscape, Hokusai art style"
- Stable Diffusion 2.1 : "A landscape, Hokusai art style"
- Stable Diffusion 2.1 via NightCafe : "A landscape, Hokusai art style"
Constat : Midjourney propose des images fidèlement inspirées de l'œuvre de l'artiste, tout en y ajoutant une dimension créative.
4. Test de génération de détails : Moustaches de chat
Le prompt était : "A very detailed zoom of a cat’s whiskers".
- Midjourney : "A very detailed zoom of a cat’s whiskers"
- DALL-E 2 : "A very detailed zoom of a cat’s whiskers"
- DALL-E 2 via NightCafe : "A very detailed zoom of a cat’s whiskers"
- DALL-E via Bing Image Creator : "A very detailed zoom of a cat’s whiskers"
- Stable Diffusion 2.1 : "A very detailed zoom of a cat’s whiskers"
Constat : Stable Diffusion a plutôt bien respecté les consignes, avec des résultats qui pourraient être améliorés par un ajustement des prompts.
5. Test de génération de logo : "Better Days"
Le prompt était : "A brand logo for a record label named Better Days".
- DALL-E 2 : "A brand logo for a record label named Better Days"
- DALL-E 2, via NightCafe : "A brand logo for a record label named Better Days"
- DALL-E via Bing Image Creator : "A brand logo for a record label named Better Days"
Constat : Un point faible majeur pour les trois IA testées est leur incapacité à reproduire du texte de manière fiable. Aucune des IA n'a réussi à intégrer le texte demandé dans le design du logo.
Créer une IDENTITÉ GRAPHIQUE de A à Z
6. Test d'imagination : Monde imaginaire
Le prompt était : "An imaginary world on no common basis".
- Midjourney : "An imaginary world on no common basis"
- DALL-E 2 : "An imaginary world on no common basis"
- DALL-E 2 via NightCafe : "An imaginary world on no common basis"
- DALL-E via Bing Image Creator : "An imaginary world on no common basis"
- Stable Diffusion 2.1 : "An imaginary world on no common basis"
- Stable Diffusion 2.1 via NightCafe : "An imaginary world on no common basis"
Constat : Les mondes imaginaires générés révèlent les sources d'inspiration de chaque IA. Midjourney semble puiser dans le fantastique et l'animation japonaise, DALL-E s'oriente vers la science-fiction et la cyberculture, tandis que Stable Diffusion peut produire des résultats variés selon le support.
Conclusion du comparatif
Midjourney se positionne actuellement en tête, notamment pour le photo-réalisme d'êtres humains et l'interprétation artistique. DALL-E 2 et Stable Diffusion, bien que puissants, présentent des limites, notamment dans la reproduction de texte.
Il est également à noter que les performances d'un même outil peuvent varier considérablement selon la plateforme utilisée (site officiel, NightCafe, Bing Image Creator). Pour la génération de texte dans les logos, des outils dédiés comme Canva ou Adobe Express restent préférables.
tags: #dall #e #2 #stable #diffusion