Optimisation de Stable Diffusion avec TensorRT pour une Génération d'Images Accélérée
Dans le domaine dynamique de l'IA générative, les modèles de diffusion se distinguent comme l'architecture la plus puissante pour générer des images de haute qualité à partir d'invites textuelles. Cependant, le processus d'inférence des modèles de diffusion peut être gourmand en calculs en raison des étapes itératives de débruitage requises. Starting with NVIDIA TensorRT 9.2.0, we’ve developed a best-in-class quantization toolkit with improved 8-bit (FP8 or INT8) post-training quantization (PTQ) to significantly speed up diffusion deployment on NVIDIA hardware while preserving image quality.
Cet article aborde les performances de TensorRT avec Stable Diffusion XL. Nous présentons les différenciateurs techniques qui font de TensorRT le choix incontournable pour l'inférence Stable Diffusion à faible latence. Les recettes de quantification NVIDIA TensorRT INT8 et FP8 pour les modèles de diffusion atteignent des accélérations de 1,72x et 1,95x sur les GPU NVIDIA RTX 6000 Ada par rapport au `torch.compile` natif de PyTorch fonctionnant en FP16. L'accélération supplémentaire de FP8 par rapport à INT8 est principalement attribuée à la quantification des couches d'attention multi-têtes (MHA).
La quantification TensorRT INT8 est disponible dès maintenant, avec FP8 prévue prochainement. En plus d'accélérer l'inférence, la quantification TensorRT 8 bits excelle dans la préservation de la qualité de l'image. Grâce à des techniques de quantification propriétaires, elle génère des images qui ressemblent étroitement aux images FP16 d'origine.

Comprendre TensorRT et ses Avantages
TensorRT est le moyen le plus rapide d'exécuter l'IA sur les GPU NVIDIA RTX. TensorRT peut générer des optimisations spécifiques pour votre GPU exact pour le modèle d'IA que vous souhaitez exécuter. Ces optimisations sont appelées moteurs TensorRT (TensorRT Engines).
Qu'est-ce qu'un Moteur TensorRT ?
Les moteurs TensorRT sont des exécutables optimisés pour votre matériel spécifique et le modèle d'IA choisi. Ils sont conçus pour réduire la latence et augmenter le débit de l'inférence.
Quantification et Optimisation
Bien que le PTQ (Post-Training Quantization) soit une méthode de compression privilégiée pour réduire l'empreinte mémoire et accélérer l'inférence pour de nombreuses tâches d'IA, il ne fonctionne pas directement sur les modèles de diffusion. Les modèles de diffusion ont un processus de débruitage multi-pas unique et la distribution de sortie du réseau d'estimation du bruit à chaque pas de temps peut varier considérablement.
Dans les techniques existantes, SmoothQuant se distingue comme une méthode PTQ populaire pour activer la quantification de poids 8 bits, activation 8 bits (W8A8) pour les LLM. Malgré son efficacité, les utilisateurs rencontrent fréquemment des difficultés à définir manuellement les paramètres dans SmoothQuant. Des études empiriques ont également révélé que SmoothQuant peine à s'adapter aux diverses caractéristiques des images, limitant sa flexibilité et ses performances dans les scénarios réels.
La distribution des activations peut varier considérablement selon les pas de temps, et la forme ainsi que le style général des images sont principalement déterminés dans les premières étapes du processus de débruitage, conformément aux conclusions de Q-Diffusion.

Au lieu de cela, nous avons sélectivement utilisé les facteurs de mise à l'échelle de quantification minimums du plage de pas sélectionnée, car nous avons constaté que les valeurs aberrantes dans l'activation ne sont pas si importantes pour la qualité finale de l'image. Cette approche adaptée, que nous avons nommée Percentile Quant, se concentre sur le percentile important de la plage des pas.
Exécutez une seule commande pour générer des images avec Percentile Quant et mesurez la latence avec demoDiffusion. L'étalonnage est l'étape de quantification où les plages de la précision cible sont calculées. À l'ère de l'IA générative, disposer d'une solution d'inférence qui privilégie la facilité d'utilisation est primordial.
Installation et Utilisation de l'Extension TensorRT pour Stable Diffusion Web UI
Ce guide explique comment installer et utiliser l'extension TensorRT pour Stable Diffusion Web UI, en prenant comme exemple Automatic1111, la distribution Stable Diffusion la plus populaire.
Stable Diffusion est un modèle d'IA générative basé sur des images qui permet aux utilisateurs de générer des images à partir de descriptions textuelles simples. Les utilisateurs accèdent généralement à ce modèle via des distributions qui lui fournissent une interface utilisateur et des fonctionnalités avancées.
Prérequis
- Une installation de Stable Diffusion Web UI (par exemple, Automatic1111).
- Un GPU NVIDIA compatible TensorRT.
- CUDA Toolkit installé et configuré.
Étapes d'Installation
-
Installation de Stable Diffusion Web UI (si nécessaire) : Si vous avez déjà Stable Diffusion Web UI d'Automatic1111 installé, passez à l'étape suivante. Ces instructions utiliseront l'installation autonome.
- Téléchargez le fichier `update.bat` (ou le script d'installation approprié pour votre distribution).
- En cliquant sur le fichier `update.bat`, vous pourriez recevoir un avertissement de la part de Windows. Cliquez sur "Exécuter".
- Cliquez sur `Run.bat`. Le processus d'installation commencera, et les fichiers nécessaires seront téléchargés et installés sur votre ordinateur.
- Une page web similaire à celle-ci devrait également apparaître.
-
Installation de l'Extension TensorRT :
- Rendez-vous dans l'onglet "Extensions" de votre Stable Diffusion Web UI.
- Cliquez sur l'onglet "Install from URL".
- Entrez l'URL du dépôt de l'extension TensorRT (par exemple, le dépôt officiel ou un fork recommandé).
- Cliquez sur "Install".
- Une fois l'installation terminée, cliquez sur l'onglet "Installed", assurez-vous que la case de l'extension TensorRT est cochée, puis cliquez sur "Apply and restart UI". L'interface utilisateur se rafraîchira.
Génération des Moteurs TensorRT
Vous devez d'abord installer l'extension et générer des moteurs optimisés avant d'utiliser l'extension. Elle prend en charge Stable Diffusion 1.5, 2.1, SDXL, SDXL Turbo et LCM.
-
Génération des Moteurs par Défaut :
- Cliquez sur le bouton "Generate Default Engines".
- Cette étape prend 2 à 10 minutes en fonction de votre GPU.
- La sélection "Export Default Engines" ajoute la prise en charge des résolutions entre 512 x 512 et 768x768 pour Stable Diffusion 1.5 et 2.1 avec des tailles de lot de 1 à 4.
- Notez que la première fois que vous exécutez ce processus, l'extension générera un modèle ONNX optimisé par TensorRT.
-
Génération de Moteurs Personnalisés :
- Vous pouvez générer autant de moteurs optimisés que vous le souhaitez.
- Les moteurs dynamiques prennent en charge une plage de résolutions et de tailles de lot, avec un léger coût en performance.
- Les moteurs statiques ne peuvent être configurés que pour correspondre à une seule résolution et taille de lot. Les moteurs statiques offrent les meilleures performances au détriment de la flexibilité.
- Les moteurs dynamiques peuvent être configurés pour une plage de résolutions de hauteur et de largeur, et une plage de tailles de lot.
- L'extension TensorRT vous permet de créer à la fois des moteurs statiques et dynamiques et choisira automatiquement le meilleur moteur pour vos besoins.
- Vous pouvez voir les moteurs qui étaient précédemment disponibles en bas de la page dans la section "Available TensorRT engine-profiles".
- Chaque préréglage peut être ajusté avec l'option "Advanced Settings".
Utilisation des Moteurs Générés
-
Configuration de l'Interface Utilisateur :
- Allez dans Settings → User Interface → Quick Settings List.
- Ajoutez sd_unet à la liste des paramètres rapides.
- La partie supérieure de l'interface utilisateur comportera désormais une nouvelle liste déroulante pour SD Unet.
-
Sélection du Moteur :
- Le moteur par défaut sera automatiquement sélectionné dans la liste déroulante "Preset".
- Le nom du moteur indique le point de contrôle Stable Diffusion pour lequel ce moteur a été généré.
-
Génération d'Images :
- Vous pouvez maintenant aller dans l'onglet text2img et commencer à générer des images avec des performances optimisées.
Optimisation pour les Checkpoints Spécifiques (LoRA, LyCORIS)
Pour utiliser les checkpoints LoRA / LyCORIS, ils doivent d'abord être convertis au format TensorRT.
-
Exportation du Modèle :
- Exportez le modèle.
- Cela ajoute la possibilité de convertir le module Unet du modèle chargé en TensorRT.
- Nécessite une version au moins postérieure au commit 339b5315 (actuellement, c'est la branche de développement après le 27-05-2023).
- Les LoRA sont intégrés dans le modèle converti. Le support Hypernetwork n'est pas testé. ControlNet n'est pas pris en charge.
Considérations Techniques et Spécifiques
HIRES FIX
Si vous utilisez l'option hires.fix dans Automatic1111, vous devez construire des moteurs qui correspondent à la fois aux résolutions de départ et de fin.
Résolution
Lors de la génération d'images, la résolution doit être un multiple de 64.
Problèmes d'Installation
Installation échouée ou onglet TensorRT absent de l'interface utilisateur : Ceci est très probablement dû à une installation échouée. Assurez-vous d'avoir la même version de CUDA que celle utilisée par la bibliothèque `torch` de Python.
Versions Spécifiques de Stable Diffusion
-
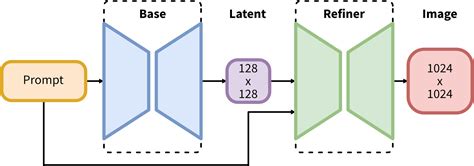
Repository TensorRT pour SDXL : Ce dépôt héberge les versions TensorRT (sdxl, sdxl-lcm, sdxl-lcmlora) de Stable Diffusion XL 1.0 créées en collaboration avec NVIDIA. Voir les instructions d'utilisation pour savoir comment exécuter le pipeline SDXL avec les fichiers ONNX hébergés dans ce dépôt. La première invocation produit des fichiers de plan dans engine_xl_base et engine_xl_refiner spécifiques à l'accélérateur exécuté et sont réutilisés pour les invocations ultérieures.
-
Repository TensorRT pour Stable Diffusion 3.5 Large : Ce dépôt héberge la version TensorRT optimisée de Stable Diffusion 3.5 Large, développée en collaboration entre Stability AI et NVIDIA. Stable Diffusion 3.5 Large est un modèle Multimodal Diffusion Transformer (MMDiT) texte-vers-image qui offre des performances améliorées en termes de qualité d'image, de typographie, de compréhension des invites complexes et d'efficacité des ressources. Ce dépôt contient les exportations ONNX des modèles T5, MMDiT et VAE en précision BF16. Il contient également le modèle MMDiT en précision FP8. Pour télécharger les checkpoints du modèle pour Stable Diffusion 3.5, veuillez demander l'accès sur la page Stable Diffusion 3.5 Large. Vous devrez ensuite obtenir un jeton d'accès en lecture à HuggingFace Hub et exporter comme indiqué ci-dessous.
-
Repository TensorRT pour Stable Diffusion 3 Medium : Ce dépôt héberge la version TensorRT de Stable Diffusion 3 Medium créée en collaboration avec NVIDIA. Le MMDiT dans Stable Diffusion 3 Medium peut être optimisé davantage avec la quantification INT8 à l'aide de TensorRT Model Optimizer. L'accélération de bout en bout estimée comparant TensorRT fp16 et TensorRT int8 est de 1,2x ~ 1,4x sur divers GPU NVIDIA. L'économie de mémoire est d'environ 2x pour le moteur MMDiT int8 par rapport à son homologue fp16. Fonctionne mieux pour les images 1024x1024. La première invocation produit des fichiers de plan dans --engine-dir spécifiques à l'accélérateur exécuté et sont réutilisés pour les invocations ultérieures.
API et Mises à Jour
L'API a entraîné la non-mise à jour du fichier model.json.
Conditionnement d'Image
Fournissez un conditionnement d'image d'entrée en utilisant ci-dessous.
Tutoriel 1: Creer sa premiere image IA en local, STABLE DIFFUSION, FORGEUI
tags: #stable #diffusion #tensorrt