Vectorisation Spark : Définition et Concepts Clés
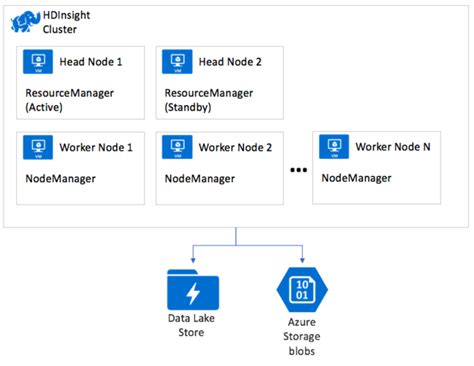
Apache Spark ML est un module de bibliothèque qui s’exécute sur Apache Spark d’apprentissage. Spark lui-même est un environnement de cluster qui fournit aux ingénieurs de données et aux chercheurs de données une interface de programmation pour gérer un ensemble d'ordinateurs avec parallélisme des données et tolérance de panne. Spark prend en charge un nombre de langages tels que Scala, Java, Python et R. Il fournit également nativement un service de bloc-notes Jupyter.
Pour utiliser Spark ML, la première étape consiste à créer un cluster Spark. Cela peut se faire via le portail Azure en choisissant "Créer une ressource", puis HDInsight. Le premier panneau de configuration concerne les concepts de base et traite des propriétés essentielles du cluster, telles que le nom du cluster, les informations d'identification de l'administrateur SSH, ainsi que le groupe de ressources et l'emplacement. Le nom du cluster doit être unique dans le domaine azurehdinsight.net. Une option importante est le "Type de Cluster", qui permet de définir le type de cluster sur Apache Spark et la version 2.10 de Spark (HDI 3.6).
Configuration du Stockage et du Cluster Spark
L'étape suivante consiste à configurer les options de stockage pour le cluster. Il est recommandé de laisser le Type de stockage principal et la méthode de sélection à leurs valeurs par défaut. Pour le conteneur de stockage, il est possible de le créer en cliquant sur "Créer" et en le nommant, par exemple, "msdnsparkstorage", puis de définir le conteneur par défaut pour "sparkstorage".
Avant de finaliser la configuration, un écran de résumé permet de vérifier et de modifier les paramètres du cluster, ainsi que d'estimer son coût horaire. Il est essentiel de toujours supprimer les clusters inutilisés, car contrairement aux machines virtuelles dans Azure, les clusters HDInsight n'offrent pas d'option pour suspendre et arrêter la facturation.
Système de Fichiers Distribués et Chargement des Données
Spark, à l'instar de Hadoop, utilise le système de fichiers distribués Hadoop (HDFS) comme magasin de fichiers à l'échelle du cluster. HDFS est conçu pour stocker de grands ensembles de données et les rendre rapidement accessibles aux applications s'exécutant sur le cluster de manière fiable. Dans les clusters HDInsight, les objets BLOB de stockage Azure sont transparentement mappés à HDFS, ce qui facilite le chargement et le téléchargement de données vers et depuis le magasin de fichiers HDFS attaché au cluster Spark.
Pour commencer à travailler avec des données, l'outil Explorateur de stockage Azure peut être utilisé pour télécharger des fichiers. L'Explorateur de stockage Azure est un utilitaire gratuit et multiplateforme pour gérer les magasins de données dans Azure. Une fois le cluster configuré et l'Explorateur de stockage Azure configuré pour accéder au compte de stockage, il est possible de naviguer jusqu'à l'objet blob "msndemo" et de créer un nouveau dossier, par exemple "vols". Ensuite, le bouton de téléchargement permet de charger un fichier de données CSV.
Introduction à PySpark et aux Notebooks Jupyter
L'API Python de Spark, communément appelée PySpark, expose le modèle de programmation Spark pour Python. Pour les développeurs familiers avec Python, PySpark apparaîtra très familier. L'implémentation HDInsight d'Apache Spark inclut une instance de bloc-notes Jupyter déjà en cours d'exécution sur le cluster. Pour y accéder, il suffit de se rendre sur le panneau du cluster Spark dans le portail Azure, puis sous l'onglet "Vue d'ensemble", de cliquer sur l'un des éléments étiquetés "Tableau de bord du Cluster". Dans le panneau qui s'affiche, cliquez sur la vignette "Bloc-notes Jupyter".
Cela ouvre un bloc-notes vide avec une cellule. Dans cette première cellule, un code peut être entré pour charger le fichier CSV précédemment téléchargé. Il est important de noter le gestionnaire de protocole "wasb" dans l'URL. WASB signifie "Windows Azure Storage Blob" et fournit une interface entre Hadoop et Azure Blob storage. Les objets BLOB Azure peuvent agir comme des magasins de données permanents, même lorsque le cluster Spark n'est pas en cours d'exécution.
Chargement et Exploration des Données avec les DataFrames
En exécutant le code dans la cellule (par exemple, en appuyant sur CTRL + ENTRÉE), l'espace sous la cellule indiquera "Application Spark en cours de démarrage". Après quelques instants, un tableau apparaîtra avec des informations sur le travail exécuté, et une notification indiquera que la "SparkSession est disponible en tant que 'spark'". Les paramètres passés à la méthode `spark.read.csv` déduisent automatiquement un schéma et indiquent que le fichier comporte une ligne d'en-tête. Le contenu du fichier CSV est chargé dans un objet DataFrame.
Le schéma s'affiche, montrant le nom et le type de données de chaque champ. Dans Spark, les DataFrames sont un ensemble distribué de lignes avec des colonnes nommées. Ils fournissent une interface similaire aux tables de bases de données relationnelles ou à une feuille de calcul Excel avec des en-têtes de colonne nommés. En coulisse, les DataFrames offrent une API à une structure de données fondamentale à un niveau inférieur dans Spark : un RDD (Resilient Distributed Dataset). Les RDD sont divisés en portions plus petites appelées partitions, qui sont réparties entre les nœuds du cluster. Lorsqu'une action est effectuée sur un RDD, chacune de ses partitions lance une tâche et l'action est exécutée en parallèle.
Les DataFrames exposent plusieurs façons d'explorer les données. Par exemple, il est possible de créer un nouveau DataFrame avec des résultats filtrés à partir d'un DataFrame existant. La méthode `show` affiche les premières lignes. Les résultats peuvent être triés et un nombre spécifique de lignes peut être affiché. La manipulation des DataFrames est décrite comme simple et intuitive, le moteur de base de Spark s'occupant de la parallélisation de l'exécution des requêtes de données.
Création d'un Modèle Prédictif avec Spark ML
Pour créer un modèle prédictif avec Spark ML, il est nécessaire d'importer certaines bibliothèques et de créer un nouveau DataFrame contenant uniquement les champs nécessaires à la création d'un modèle de prévision de la probabilité qu'un vol soit retardé. Le code peut être utilisé pour réduire les colonnes d'origine du DataFrame à un nombre plus restreint. Il est également possible de créer une nouvelle colonne indiquant si un vol est retardé et de supprimer les lignes contenant des valeurs nulles, car les algorithmes ML peuvent être sensibles aux valeurs nulles inattendues.
Dans le ML supervisé, les données de terrain sont connues. Dans ce cas, il s'agit d'enregistrements de retards d'arrivée de vols aux États-Unis. Sur la base de ces données, l'algorithme génère un modèle prédictif. Les champs utilisés pour la prédiction sont appelés "caractéristiques" (features). Les modèles ML supervisés sont souvent testés avec le même jeu de données sur lequel ils sont formés, ce dernier étant divisé aléatoirement en deux jeux : un pour l'apprentissage et un pour le test.
Les données de test doivent être modifiées pour satisfaire les exigences de l'algorithme ML via un processus appelé vectorisation, où les champs représentant les caractéristiques sont combinés dans un tableau ou un vecteur. La colonne indiquant le retard est renommée "label" (étiquette). Le DataFrame d'entraînement aura alors deux colonnes : "features" et "label".
Application d'un Modèle de Régression Logistique
Avec les données d'apprentissage préparées, elles sont fournies à un algorithme ML. La régression logistique est une méthode statistique pour analyser les données où une ou plusieurs variables d'entrée influencent un résultat. Pour ce modèle, les variables d'entrée sont les caractéristiques (Jour du mois, Jour de la semaine, ID de l'aéroport d'origine, ID de l'aéroport de destination, Délai de départ), et le résultat est la colonne d'étiquette (si le vol a été retardé de plus de 10 minutes).
Le modèle est créé en ajustant les données d'apprentissage. Le modèle formé est ensuite testé. Les données de test doivent également être préparées en les exécutant via l'assembleur de vecteur. L'étape suivante consiste à exécuter les données d'apprentissage à travers le modèle en appelant la méthode de transformation. La sortie est un DataFrame avec les caractéristiques, la valeur prédite, la valeur réelle et la probabilité.
Évaluation et Amélioration du Modèle
L'évaluation de l'efficacité du modèle est cruciale. Une mesure courante est la "matrice de confusion", qui affiche le nombre de vrais négatifs et positifs, ainsi que le nombre de faux positifs et de faux négatifs. Les résultats peuvent indiquer que le modèle est plus souvent incorrect que correct.
En cas d'échec des expériences, il est conseillé d'analyser les résultats, de modifier les paramètres du modèle et de réessayer. Des facteurs tels que la granularité de l'intervalle de retard (10 minutes), le nombre de champs d'entrée, ou la quantité de données historiques peuvent influencer la précision du modèle.
Architecture et Composants d'Apache Spark
Apache Spark est un environnement informatique de cluster rapide et puissant pour le traitement parallèle des charges de travail de données avec une architecture modulaire. Deux modules décrits sont PySpark et Spark ML. PySpark fournit un runtime Python exécutant Spark et une abstraction de haut niveau des RDD sous la forme d'une API DataFrame.
Spark Core
Spark Core est le moteur d'exécution du framework, la base du framework. Il fournit la répartition des tâches distribuées, la planification et les fonctionnalités de base de lecture/écriture.
Spark Streaming
Spark Streaming est la partie traitement en quasi temps réel d'Apache Spark. Il traite les données sous forme de mini-batchs espacés par un instant T.
MLlib
MLlib utilise des RDD avec des types spécifiques pour les algorithmes d'apprentissage automatique. Les entrées des algorithmes doivent être des RDD[Vector], des RDD[LabeledPoint] ou des RDD[Rating].
GraphX
GraphX est un framework de traitement de graphe distribué sur Spark, fournissant une API pour le calcul de graphes.
Optimisations et Fonctionnalités de Spark 3
La version 3 d'Apache Spark apporte des améliorations significatives, notamment en matière de performances et de fonctionnalités.
Spark SQL et Spark Catalyst
Spark SQL est un composant majeur d'Apache Spark, permettant d'exécuter directement du SQL dans Spark. Il fournit une abstraction structurée sur les RDD appelée DataFrame/DataSet. Spark s'appuie sur un moteur d'exécution de requête SQL appelé Spark Catalyst, qui optimise les plans d'exécution des requêtes.
Optimisation Basée sur les Coûts (Cost-Based Optimization - CBO)
Jusqu'à la version 2.4 de Spark, l'optimisation basée sur les coûts utilisait des estimations calculées à la compilation concernant les statistiques sur les données (nombre de lignes, valeurs distinctes, etc.) pour déterminer le plan d'exécution optimal. Cependant, dans un système distribué comme Spark, les statistiques des données peuvent changer à chaque étape du traitement.
Optimisation Dynamique d'Exécution (Adaptive Query Execution - AQE)
AQE améliore le workflow d'optimisation de Spark Catalyst en ajustant le plan d'exécution des requêtes au moment de l'exécution, à chaque étape du job. Il recalcule les statistiques des données et reconstruit le plan d'exécution si nécessaire. AQE peut automatiquement combiner, réduire ou augmenter le nombre de partitions de shuffle, optimiser les jointures (broadcast-join), et gérer l'asymétrie des tailles de partition.
PySpark et Koalas
PySpark est l'API Python de Spark, très populaire pour le Big Data. Koalas est une implémentation distribuée de la bibliothèque Pandas, offrant une API Pandas automatiquement distribuée en Spark et compatible avec les types de la JVM. Koalas s'appuie sur Apache Arrow pour des performances accrues.
Intégration de RocksDB dans Spark Streaming
Spark Streaming peut désormais utiliser RocksDB pour la persistance des états des traitements en quasi temps réel, offrant une meilleure gestion des états par rapport aux RDD.
Nouvelle Interface WebUI
L'interface WebUI de Spark a été améliorée pour faciliter le monitoring et le débogage des jobs Spark, y compris une interface plus détaillée pour le monitoring des jobs de streaming.
Prise en Compte des GPU dans le Deep Learning
Spark 3 supporte le Deep Learning via le projet Hydrogen, permettant d'accélérer l'apprentissage des modèles en utilisant les GPU.
Modes d'Exécution et Accès aux Fonctionnalités Spark
Il faut faire la différence entre lancer un traitement Spark en mode standalone et en mode local. SparkContext est le point d'accès à toutes les fonctionnalités de Spark. Cependant, depuis Apache Spark 2.0, SparkSession offre un point d'entrée unifié.
Lorsqu'un worker exécute un traitement Spark, un exécuteur (ou plusieurs) est lancé. Les exécuteurs sont des JVM séparées qui se connectent à l'instance Driver, qui leur envoie les tâches à exécuter.
La Spark UI est l'interface web des applications Spark, permettant de surveiller et d'inspecter les exécutions des jobs Spark. Pour les utilisateurs de Python, PySpark est construit sur l'API Java de Spark.
D'autres systèmes open source, comme Nomad, peuvent jouer le rôle de gestionnaire de ressources pour un cluster Spark.
Apache Spark en 100 secondes
tags: #vectorisation #spark #definition